很早的时候就知道,OkHttp在io层面上的操作是由Okio代为完成的,所以实际意义上和Socket打交道的应该是Okio。而Okio又比传统的java io要高效。所以,在分析OkHttp之前,有必要针对Okio的一些方法进行展开,作为后面读写操作的铺垫。
Okio -> OkHttp -> Picaso -> Retrofit
Okio版本 1.13.0
OkHttp版本 3.8.0

1. Okio与java io相比的优势
java的InputStream可以被查看成是一个数据的来源,调用read方法从中读取数据。由于有些文件特别大,我们不可能在内存中分配一个和文件大小一样大的字节数组来专门来读写文件。因此需要传入一个缓冲数组。所以一般的读写程序的代码是这么写的
public abstract class InputStream implements Closeable{
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
}
public static void main(String[] args) throws Exception {
// 指定要读取文件的缓冲输入字节流
BufferedInputStream in = new BufferedInputStream(new FileInputStream("F:\\test.jpg"));
File file = new File("E:\\test.jpg");
if (file != null) {
file.createNewFile();
}
// 指定要写入文件的缓冲输出字节流
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
byte[] bb = new byte[1024];// 用来存储每次读取到的字节数组
int n;// 每次读取到的字节数组的长度
while ((n = in.read(bb)) != -1) {
out.write(bb, 0, n);// 写入到输出流
}
out.close();// 关闭流
in.close();
}
BufferedInputStream和BufferedOutputStream就是提供了这样的缓冲策略,其内部默认分配了一个默认大小的字节数组,或者在read方法中传入一个字节数组,每次一个byte一个byte的读,然后将读出来的内容写进outPutStream。读到-1就是文件终止(EOF)。具体原理可以参考IBM的深入分析 Java I/O 的工作机制。
那么问题来了,buffer[]作为一个字节数组,其容量是恒定的。假设我们想要一次性读取特别多的数据怎么办。例如http的response header一般长这样,然而实际上在无线电传播的过程中,每一行的后面都跟了一个换行符’\r\n’,而且无线电传播的时候其实根本没有换行的概念,就是一个字节跟着一个字节。假如服务器自己定义了特别长的header字段,inputstream读到这里的时候,事先预设的字节数组(没法改了)装不下,一种简单粗暴的方式是尝试扩容,这就意味着要把数据从原始数组copy到新的数组,丢掉旧的数组,把指针指向新的数组(一个是allocate数组,一个是arrayCopy,这俩都造成了性能损耗),当然jdk肯定不是这么干的。
BufferedInputStream是用来做提供了缓存的效果,DataInputStream提供了读取基本数据类型的功能(比方说4个bytes当成一个int),InputStreamReader的read方法需要提供一个char[],然后外部拿着这个char[]去生成一个String.
HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: 0xc8f942640001e753
Bduserid: 0
Cache-Control: private
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Fri, 21 Jul 2017 15:35:58 GMT
Expires: Fri, 21 Jul 2017 15:35:29 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=0; path=/
Set-Cookie: H_PS_PSSID=1428_21110_20930; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
Vary: Accept-Encoding
X-Powered-By: HPHP
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
对于Http这种频繁的读写操作,allocate数组和copy数据无形中减慢了网络访问的速度。
- Okio的解决方案
Buffer buffer = new Buffer();//cheap ,allocation literal nothing
buffer.writeUtf8("Hello Okio"); //java中一个英文字符占一个字节(byte),一个汉字占2个字节(byte)
buffer.writeUtf8("you can "); //可以想象segment中被塞进了"you can "这几个byte
buffer.writeUtf8("Go faster");
Okio将读写操作集中到到Buffer这个类中,用Sink和Source分别代表数据的去向和来源。而数据的承载类是Segment,读取数据(read)的时候从SegmentPool中索取Segment,读到Segment的byte[]数组中,装不下了再拿一个Segment。这个过程中是没有 new byte[]操作的。
- Read from a source, write to a sink
public final class Buffer implements BufferedSource, BufferedSink, Cloneable {
Segment head;
long size;
public Buffer() {
//构造函数里不分配任何对象,所以创建一个Buffer几乎没有什么性能开销
}
final class Segment {
static final int SIZE = 8192;
static final int SHARE_MINIMUM = 1024;
final byte[] data;
int pos;
int limit;
boolean shared;
boolean owner;
Segment next;
Segment prev;
}
}
现在那个读取一个文件写到另一个文件的程序可以写成这样:
sink = Okio.sink(dstFile); //返回了一个Sink匿名类,write的时候使用public void write(Buffer source, long byteCount)方法进行写操作
source = Okio.source(srcFile);
Buffer buf = new Buffer();
for (long readCount; (readCount = source.read(buf, 2048)) != -1; ) {
sink.write(buf, readCount);
}
看起来还是在数据源和数据终点之间塞了一个缓冲层,sink(dst)和source(src)都是接口,Buffer同时实现了这俩接口。
write是从外面拿数据塞到自己的数组中,所以每次写的时候或让Buffer的Size变大(从segment pool中借用segment)。Buffer(Source)的read方法是把数据从Buffer中拿出来,所以会让Buffer的size变小(每一个Segment读完了会返回到segment pool中)
在Buffer的所有readXXX方法中都能看到这么一句话
SegmentPool.recycle(segment)
因为Buffer内部是通过Segment的next和prev实现了双向链表,write是在尾部添加数据,read是从头部读取数据并移除。
Okio能够实现高效率的核心在于,在java的inputStream和BufferedInputStream中,如果两块缓冲区之间想要交换数据。前面提到的扩容情况,从一个数组把数据复制到另一个更大的数组,必须走arrayCopy。
网上查找了很多博客,总的来说就是java io采用了装饰者模式,不同Stream之间要包一层。
写数据时,写原始数据要用DataOutputStream,使用带缓冲的写要用BuffedOutputStream,使用字符编码要用OutputStreamWriter,写字节数组有ByteArrayOutputStream。
读数据时也是,原始数据要用DataInputStream,带缓冲的要用BufferedInputStream,字符编码要用InputStreamReader,读字节数有ByteArrayInputStream。
来看下其中带buffer的装饰类是怎么创建的,顺便把java io批判一下。
ByteArrayOutPutStream baos = new ByteArrayOutPutStream();
ByteArrayInputStream bis = new ByteArrayInputStream(baos.toByteAarray()); //toByteArry内部调用了Arrays.copyOf(),创建了新对象
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size]; //创建新数组
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size]; //创建数组
}
同样的事情在okio中是这么干的
RealBufferedSource(Source source) {
if(source == null) {
throw new NullPointerException("source == null");
} else {
this.source = source; //其实是buffer
}
}
RealBufferedSink(Sink sink) {
if(sink == null) {
throw new NullPointerException("sink == null");
} else {
this.sink = sink; //只是挪一下指针
}
}
由于一个Buffer即是source也是sink,挪一下指针就行了。写的时候往链表的尾巴写,读的时候从链表的头部读,读完了segment回收。
BufferedInputStream要求外部调用者带着一个固定大小的byte数组来取数据,难免会有人传进来一个特别小的数组,这样永远不可能读取超过这个数组大小长度的某一行。
读写这种事情操作起来总是从一个近似无限大的数据源 一点一点地取出来 存在一个内存中一个临时的地方, 然后再讲这部分数据交给其他接收方。 这就要求所有的读写都要准备进行多次读写,每次读到一个中转站中。在java io中这个中转站的大小是固定的,okio中这个中转站是一个个的Segment连接起来的。
java io中各种decorater流之间的包装带来了System.arrayCopy
new DataInputStream(new BufferedInputStream(new FileInputStream("")));
`
上面DataInputStream通常用于方便的读取基本数据类型,比如readChar,readLong,readByte等等.
例如 dataInputstream.readByte -> BufferedInputStream.read -> FileInputStream.read在BufferedInputStream中有一层byte[] buf. BufferedInputStream的read有两种,一是一次读一个byte,一种是外部传一个byte,指定offset和len。第一种要经历fill方法,第二种则是先填满自己的buf,然后System.arraycopy到外部传入的dst数组中。当然如果外界要求的len超出buff.length,那么直接跳过buf这一层。
调用fill方法的前提是发现pos >= count ,也就是是说提前预读取的数据不够了,fill方法主要是从0开始重新从底层读取数据,期望从底层读取buf.length - pos 个数据
pos = 0; /* no mark: throw away the buffer */
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos; //所以理想情况下,每次fill方法的调用都会往buf里面塞8192个byte, count = 8192 , pos = 0.下一个read从0开始,同时已经预读取了一部分数据,从pos到count的数据都是下一次read可以直接读的。这里面并不涉及arrayCopy.
xxxOutputSream中常常看到这样一句话
/ If the request length exceeds the size of the output buffer,
flush the buffer and then write the data directly. In this
way buffered streams will cascade harmlessly. /
回顾BufferedInputStream和BufferedOutputSream存在的主要意义是预防那种数据很少的读写,如果是一次性的大批量读取,则直接跳过buff一层。
在jake wharton的forcing-bytes-downward-in-okio 中有这么一段话
With java.io.* streams, however, multiple levels of buffering require each level to allocate and manage its own byte[]. This means that a flush operation will result in each level doing an arraycopy() of its data down to the next level (which also might have required buffer expansion).
查了下BufferdOutputStream.flush
// 1.
public synchronized void flush() throws IOException {
flushBuffer();
out.flush();
}
// 2
private void flushBuffer() throws IOException {
if (count > 0) {
out.write(buf, 0, count);
count = 0;
}
}
// 3.1 BuuferdOutputStream的write方法
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) {
/* If the request length exceeds the size of the output buffer,
flush the output buffer and then write the data directly.
In this way buffered streams will cascade harmlessly.
超过大小直接跳过缓存
*/
flushBuffer();
out.write(b, off, len);
return;
}
if (len > buf.length - count) {
flushBuffer();
}
System.arraycopy(b, off, buf, count, len); //这里一定会走到arrayCopy
//假设
count += len;
}
// 3.2 ByteArrayOutputStream的write方法
public synchronized void write(byte b[], int off, int len) {
if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) - b.length > 0)) {
throw new IndexOutOfBoundsException();
}
ensureCapacity(count + len);
System.arraycopy(b, off, buf, count, len);
count += len;
}
// 3.3 BufferedWriter(虽然已经不算stream了)
public void write(char cbuf[], int off, int len) throws IOException {
synchronized (lock) {
while (b < t) {
int d = min(nChars - nextChar, t - b);
System.arraycopy(cbuf, b, cb, nextChar, d);
b += d;
nextChar += d;
if (nextChar >= nChars)
flushBuffer();
}
}
}
都是arrayCopy,可以想象,一层层的flush调用传递下来,每一层的buffer都会被通过arrayCopy的方式传递到下一层。比方说,包了3层BufferdOutputStream就要arrayCopy三次,极其费事。
//在Okio中,不存在这样的copy,
//Buffer的定义是”A collection of bytes in memory.”,与数组不同,Buffer之间传递数据的方式是挪指针。
BufferedSource在读取Socket数据时,一边从socket里面拿一个Segment大小的数据,然后调用readInt,readLong等方法返回int,long(同时从segment头部清空数据)。如果读到segment最后发现剩下的byte不能组成一个int,就会从segment pool中借一个segment,并从socket中读取数据塞满,把第一个segment剩下的一点byte和第二个segment的头部一点拼成一个int。以BufferSource的readInt为例:
public int readInt() {
if(this.size < 4L) {
throw new IllegalStateException("size < 4: " + this.size);
} else {
Segment segment = this.head;
int pos = segment.pos;
int limit = segment.limit;
if(limit - pos < 4) { //一个int 4个byte,这时候segment中未读的数据只剩下不到4个了
return (this.readByte() & 255) << 24 | (this.readByte() & 255) << 16 | (this.readByte() & 255) << 8 | this.readByte() & 255; //readByte就是从链表的头部开始一个byte一个byte的读,segment读完了自动回收,直到组成一个int。
} else { //剩下的byte足够组成一个int
byte[] data = segment.data;
int i = (data[pos++] & 255) << 24 | (data[pos++] & 255) << 16 | (data[pos++] & 255) << 8 | data[pos++] & 255; //从byte转int
this.size -= 4L;
if(pos == limit) {
this.head = segment.pop();
SegmentPool.recycle(segment); //读完了就把segment回收
} else {
segment.pos = pos;
}
return i;
}
}
}
一个很有意思的现象是,java BufferedInputStream的默认buffer数组大小是8192,okio 的segment的默认size也是8192,这些都是以byte为单位的。找到一个合理的解释。大致意思是8192 = 2^13, windows和linux上这个大小正好占用两个分页文件(8kB)。另外java io的类图确实让人眼花缭乱。
2. OkHttp的解析
2.1 使用介绍
先上一张图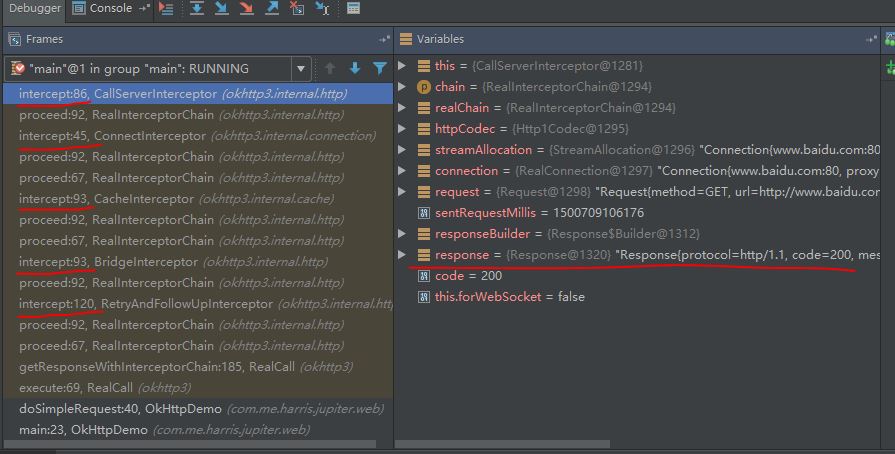 。这是最简单的直接用OkHttpClient请求百度首页的堆栈调用情况。在没有做任何手动配置的情况下,至少发现了五个Interceptor:
。这是最简单的直接用OkHttpClient请求百度首页的堆栈调用情况。在没有做任何手动配置的情况下,至少发现了五个Interceptor:
RetryAndFollowUpInterceptor
BridgeInterceptor
CacheInterceptor
ConnectInterceptor
CallServerInterceptor // 这里面没有再调用chain.proceed,所以责任链到此返回
走到CallServerInterceptor的时候,可以看到Response已经形成了。轮到每一个Interceptor的intercept(Chain )方法执行的时候,传入的都是一个new 的RealInterceptorChain,只不过index+1了(其实唯一变化的也就只有这个index了)(而一般写interceptor的时候直接拿着传入的chain.proceed就可以了)
首先是调用者的代码
mClient = new OkHttpClient()
//同步执行
Request request = new Request.Builder()
.url("http:www.baidu.com")
.build();
Call call = mClient.newCall(request);
Response response = null;
try {
response = call.execute();
} catch (IOException e) {
e.printStackTrace();
}
//异步执行代码
Request request = new Request.Builder()
.url("http:www.baidu.com")
.build();
Call call = mClient.newCall(request);
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
2.2 参数配置
首先Request.Builder().build()方法,这里面只是使用Builder模式,和Retrofit很相似,方便链式调用。最终调用了Request的构造函数
Request(Request.Builder builder) {
this.url = builder.url; //HttpUrl类型
this.method = builder.method; //String类型
this.headers = builder.headers.build(); //header就是个字典,内部用一个String数组维护。
this.body = builder.body;// RequestBody类型,用于POST提交表单或者Multipart上传文件。
this.tag = builder.tag != null?builder.tag:this; //Object类型
}
Request里面的成员代表了一个网络请求所应该有的一切可能的元素,没什么可说的。
OkHttpClient的构造也是Builder模式,一旦创建了不能setXX.找到一个比较丰富的例子
client = new OkHttpClient.Builder()
.retryOnConnectionFailure(true)
.connectTimeout(15, TimeUnit.SECONDS)
//设置缓存
.cache(cache)
.build();
到这里都还只是发起真正的请求之前的configuration阶段,来看发起RealCall的过程
Call call = mClient.newCall(request);
这里面初始化了一个RetryAndFollowUpInterceptor。这个拦截器的作用是在连接server失败后自动重连,但服务器500就不会重连,参考okhttp-is-quietly-retrying-requests-is-your-api-ready
2.3 开始执行请求
response = call.execute();
@Override public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
try {
client.dispatcher().executed(this);//这里只是把realCall添加到了Disptcher的RunningSyncall这个deque中,只是为了记个数,以及方便cancel
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
client.dispatcher().finished(this);//从deque中移除
}
}
重点就在getResponseWithInterceptorChain里面
Response getResponseWithInterceptorChain() throws IOException {
List<Interceptor> interceptors = new ArrayList();
interceptors.addAll(this.client.interceptors());
interceptors.add(this.retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(this.client.cookieJar()));
interceptors.add(new CacheInterceptor(this.client.internalCache()));
interceptors.add(new ConnectInterceptor(this.client));
if(!this.forWebSocket) {
interceptors.addAll(this.client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(this.forWebSocket));
Chain chain = new RealInterceptorChain(interceptors, (StreamAllocation)null, (HttpCodec)null, (RealConnection)null, 0, this.originalRequest);
return chain.proceed(this.originalRequest);
}
注意顺序,用户手动添加的interceptor是最先添加的。在添加完ConnectInterceptor之后,又添加了networkInterceptors(用户手动添加的,一个List)。道理也很清楚,一种是在发起Socket请求之前就拦下来,一种是连上Socket之后的拦截
Chain的proceed就是从List中一个个取出Interceptor,然后执行
关于异步请求的线程池问题,异步请求实际的调用是这样的
Dispatcher.java
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);//当前运行的异步任务少于maxRequest,并且针对当前host发起的请求少于maxRequestsPerHost(默认是5个,也就是默认同时只能对1个域名发起5个请求,这个跟浏览器很像)
executorService().execute(call);// 丢给线程池
} else {
readyAsyncCalls.add(call);//添加到队列中去
}
}
/** Ready async calls in the order they'll be run. */
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>(); //排队等待被执行的异步任务
/** Running asynchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();//正在运行中的异步任务
/** Running synchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();//同步的运行的或者已经被取消的请求
异步请求:
和浏览器相似,okhttp client也设定了客户端同时只能对一个host发起有上限的连接数(5个),并且,所有的请求总数加在一起不超过64个。超过的加到一个Deque中,等异步任务执行完成后,有一个finally,这里面有一个promoteCalls,就是说可以去消费刚才排队的请求了。
同步请求:
而RealCall的execute方法就完全是一个在当前线程中执行的方法,没有任何限制,只是将这个请求加入了Dispatcher的runningSyncCalls中去了
所以,对于使用enqueue方法的应用,如果同时1s内对一个host发起的请求超过了5个,并且网络也特别差的情况下,需要等到至少timeout(connectTimeout)-1s的时间后才能轮到后续的请求执行。使用execute方法的则不受限制。
用户感知到的延时是:网络请求的时间 = 队列等待时间+dns解析时间+socket连接时间+socket io时间
OkHttpClient.Builder httpClientBuilder = new OkHttpClient.Builder()
.readTimeout(30, TimeUnit.SECONDS)
.connectTimeout(30, TimeUnit.SECONDS)
.writeTimeout(30, TimeUnit.SECONDS)
.addInterceptor(new HeaderInterceptor())
关于timeout,外部设置的时候可以设定的超时包括: 连接socket的超时,读超时,写超时
连接socket超时是直接调用socket.setSoTimeout实现的,这个是指,对这个socket的read操作只会堵塞这么长时间(就是说假如这么长时间内没有数据),之后跑出一个SocketTimeoutException。
3. 自带的五个Interceptor
3.1 RetryAndFollowUpInterceptor
while(!this.canceled) {
Response response = null;
boolean releaseConnection = true;
try {
response = ((RealInterceptorChain)chain).proceed(request, this.streamAllocation, (HttpCodec)null, (RealConnection)null);
releaseConnection = false;
} catch (RouteException var13) {
releaseConnection = false;
continue;
} catch (IOException var14) {
releaseConnection = false;
continue;
} finally {
if(releaseConnection) {
this.streamAllocation.streamFailed((IOException)null);
this.streamAllocation.release();
}
}
Request followUp = this.followUpRequest(response);
if(followUp == null) {
return response;
}
++followUpCount;
if(followUpCount > 20) {
this.streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
}
这里面写死了一个循环,只要没有cancel,catch到特定的Exception就一直让链条走下去。
3.2 BridgeInterceptor
这是第二个Interceptor
interceptors.add(new BridgeInterceptor(this.client.cookieJar()));//注意带进来了cookie,主要都是添加header什么的
public Response intercept(Chain chain) throws IOException {
Request userRequest = chain.request();
if(userRequest.header("Host") == null) {
requestBuilder.header("Host", Util.hostHeader(userRequest.url(), false));
}
Response networkResponse = chain.proceed(requestBuilder.build());
okhttp3.Response.Builder responseBuilder = networkResponse.newBuilder().request(userRequest);
}
return responseBuilder.build();
}
都是些Host,Connection Keep-Alive,User-Agent,Content-Length等跟header有关的东西。随后将request交给链条的下一个interceptor。Response回来之后相应set-Cookie这些东西,下次请求带上cookie,这些都是Http的标准步骤。
3.3 CacheInterceptor
接下来轮到cache,对于response的处理也是差不多的过程
public Response intercept(Chain chain) throws IOException {
Response cacheCandidate = this.cache != null?this.cache.get(chain.request()):null;
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
Response networkResponse = null;
networkResponse = chain.proceed(networkRequest);
Response response;
if(cacheResponse != null) {
if(networkResponse.code() == 304) {
response = cacheResponse.newBuilder().headers(combine(cacheResponse.headers(), networkResponse.headers())).sentRequestAtMillis(networkResponse.sentRequestAtMillis()).receivedResponseAtMillis(networkResponse.receivedResponseAtMillis()).cacheResponse(stripBody(cacheResponse)).networkResponse(stripBody(networkResponse)).build();
networkResponse.body().close();
this.cache.trackConditionalCacheHit();
this.cache.update(cacheResponse, response);
return response; //只针对304做了自动cache
}
Util.closeQuietly(cacheResponse.body());
}
response = networkResponse.newBuilder().cacheResponse(stripBody(cacheResponse)).networkResponse(stripBody(networkResponse)).build();
return response;
}
这里也是让请求接着走下去,response回来之后,只有304的时候才会去主动cache下来。
3.4 ConnectInterceptor
(深入okHttp 3.9.1的connectionPool以及引用计数)
在高并发的请求连接情况下或者同个客户端多次频繁的请求操作,无限制的创建连接会导致性能低下。所以OkHttp做到了对socket的复用和及时清理。
从第四个intercepter开始
ConnectInterceptor.java
public final class ConnectInterceptor implements Interceptor{
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
// 第一步,获取streamAllocation
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
// 第二步,使用streamAllocation创建(或者复用)一个httpCodec模型(即处理header和body的读写策略,具体实现包括Http1Codec和Http2Codec)
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
// 第三部,挑选出RealConnection,streamAllocation对象中的mConnection变量是在第二步里面赋值的
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
所以socket连接复用就在这句话里面了
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
StreamAllocation.java
public HttpCodec newStream(
OkHttpClient client, Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
// 省略部分,主要是这两句话
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, connectionRetryEnabled, doExtensiveHealthChecks);
//
HttpCodec resultCodec = resultConnection.newCodec(client, chain, this);
}
findHealthyConnection最终走到这里
// Attempt to get a connection from the pool.
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
}
// 判断是否isEligible的方法在RealConnection里面
// If the non-host fields of the address don't overlap, we're done.
if (!Internal.instance.equalsNonHost(this.route.address(), address)) return false;
// 只要DNS,port,protocols等host无关的参数中有一个不同就不能复用
// If the host exactly matches, we're done: this connection can carry the address.
if (address.url().host().equals(this.route().address().url().host())) {
return true; // This connection is a perfect match.
}
// 这里说明host是相同的,上面的DNS什么的都是一样的,只有后面的path,query或者RequestBody不同,那么直接复用
所以这里socket复用的方式是直接使用RealConnection持有Socket对象的引用,每一次在RealConnection的connect成功后,都会讲这个socket包装成一个BufferedSource(读取Response)和BufferedSink(往外写Request),在timeout时长内,socket不会被关闭。既然缓存就一定会有清理
在上面的findHealthyConnection中有一段
streamAllocation.acquire(connection, true);
这里面的作用就是将这条请求(Stream)添加到当前连接承载的一个List<Reference
ConnectionPool中有一个Executor,目的就是执行一个cleanupRunnable的Runnable,这里面的清理操作大致如下:
long cleanup(long now) {
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this) {
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++; //这条连接还在用
continue;
}
idleConnectionCount++; //这条连接现在空闲下来了
// If the connection is ready to be evicted, we're done.
long idleDurationNs = now - connection.idleAtNanos;// 这条连接已经多久没用到了,假如超过了闲置时间(默认5纳秒),就准备干掉这个socket
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
// We've found a connection to evict. Remove it from the list, then close it below (outside
// of the synchronized block).
// A connection will be ready to evict soon.
// All connections are in use. It'll be at least the keep alive duration 'til we run again.
// No connections, idle or in use.
}
// 在这前面如果找不到一条该被干掉的连接,直接return
closeQuietly(longestIdleConnection.socket());// 这里面就是socket.close了
// Cleanup again immediately.
return 0;
}
观察一下ConnectionPool的构造函数
/**
* Create a new connection pool with tuning parameters appropriate for a single-user application.
* The tuning parameters in this pool are subject to change in future OkHttp releases. Currently
* this pool holds up to 5 idle connections which will be evicted after 5 minutes of inactivity.
*/
// 最多保留5条闲置RealConnection(也就是底层5个Socket),每个连接(Socket)如果超过5分钟没有接客,直接干掉
public ConnectionPool() {
this(5, 5, TimeUnit.MINUTES);
}
所以,在创建Client的时候,可以把socket的缓存数量写大一点,也可以自定义一个ConnectionPool,只要实现了put,get,remove等标准的CRD操作就行了。简单来说就是自己设计一个Cache,我觉得可以根据实际的endpoint数量来设定缓存的socket的数量。
这里的interceptor方法异常简短
public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain)chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(this.client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
这里重点关注 StreamAllocation这个类
public final class StreamAllocation {
public final Address address;
private Route route;
private final ConnectionPool connectionPool;
private final Object callStackTrace;
private final RouteSelector routeSelector;
private int refusedStreamCount;
private RealConnection connection;
private HttpCodec codec;
}
从HttpCodec httpCodec = streamAllocation.newStream(this.client, doExtensiveHealthChecks); 这句话一直往下走,会走到Socket.connect(),也就是大多数人初学网络编程时被教导的如何创建Socket连接。
Stream代表一个api请求过程,RealConnection持有了真正的rawSocket。
StreamAllocation.findConnection中主要做了
1.查看当前streamAllocation是否有之前已经分配过的连接,有则直接使用
2.从连接池中查找可复用的连接,有则返回该连接
3.配置路由,配置后再次从连接池中查找是否有可复用连接,有则直接返回
4.新建一个连接,并修改其StreamAllocation标记计数,将其放入连接池中
5.查看连接池是否有重复的多路复用连接,有则清除
从连接池中找connection的判断是
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
public boolean isEligible(Address address, @Nullable Route route) {
// If this connection is not accepting new streams, we're done.
if (allocations.size() >= allocationLimit || noNewStreams) return false; //注意啊,若不是HTTP/2的连接,则allocationLimit的值总是1
///....
}
多个HTTP/1.1请求是不能在同一个连接上交叉处理(multiplexing)的,http1中一个socket只能同时处理一个stream请求,acquire类似于markInUse。这样的设计主要是为了实现HTTP/2 multi stream,http2所有stream都走一条tcp连接(一个socket)。在Http1Codec的endOfInput方法里会调用streamAllocation.streamFinished()方法,也就是说,我这stream(一次接口请求读完了,http1报文的空行读到了)用完了,socket还给pool,socket在http1场景下一次只能接一个请求。connectionPool里默认是最大5个空闲连接数(就是说最多同时存在5个没关的socket,并且每个socket如果5min内没干活,就关闭掉,因为socket也是系统资源)。
关于RouterSelector.Selection这个class,其实就是把DNS返回的多个查询record(InetSocketAddress,也就是ip地址存起来,当然存的是一个Route 对象,里头包住了InetSocketAddress)。所以可以粗略的认为一个Router对应一个ip地址吧,RouteDatabase就是一个HashSet,换ip的时候会对那些失败过的Route(ip)躲得远远的
StreamAllocation.newStream —-> StreamAllocation.findHealthyConnection —> StreamAallocation.findConnection —> new RealConnection —> RealConnection.connect
RealConnection.connect()方法
public void connect(int connectTimeout, int readTimeout, int writeTimeout, boolean connectionRetryEnabled) {
if(this.protocol != null) {
throw new IllegalStateException("already connected");
} else {
while(true) {
try {
if(this.route.requiresTunnel()) {
this.connectTunnel(connectTimeout, readTimeout, writeTimeout);
} else {
this.connectSocket(connectTimeout, readTimeout);
}
break;
} catch (IOException var11) {
if(!connectionRetryEnabled || !connectionSpecSelector.connectionFailed(var11)) {
throw routeException; //这个Exception就是给RetryAndFollowupInterceptor准备的
}
}
}
}
}
最初学习Socket编程的时候,就是写了一个while(true),是不是很像?
对了ConnectionPool内部使用了一个Deque保存RealConnection,findConnection里面有这么一段
- Internal.instance.get(this.connectionPool, this.address, this, (Route)null);//查找
- Internal.instance.put(this.connectionPool, result);//放进pool
connectSocket长这样:
private void connectSocket(int connectTimeout, int readTimeout) throws IOException {
Proxy proxy = this.route.proxy();
Address address = this.route.address();
this.rawSocket = proxy.type() != Type.DIRECT && proxy.type() != Type.HTTP?new Socket(proxy):address.socketFactory().createSocket();
this.rawSocket.setSoTimeout(readTimeout);
try {
Platform.get().connectSocket(this.rawSocket, this.route.socketAddress(), connectTimeout); //这里面就一句话socket.connect
} catch (ConnectException var7) {
ConnectException ce = new ConnectException("Failed to connect to " + this.route.socketAddress());
ce.initCause(var7);
throw ce;
}
try {
this.source = Okio.buffer(Okio.source(this.rawSocket));
this.sink = Okio.buffer(Okio.sink(this.rawSocket));
} catch (NullPointerException var8) {
if("throw with null exception".equals(var8.getMessage())) {
throw new IOException(var8);
}
}
}
重点看
this.source = Okio.buffer(Okio.source(this.rawSocket));
this.sink = Okio.buffer(Okio.sink(this.rawSocket));
通过sink往Socket里面写数据,通过source网Socket里面写数据,通过Okio包装了,虽然本质上还是socket.getOutputStream和Socket.getInputStream。到这一步,RealConnection内部sink和source初始化完成,socket已经连接上,Socket的inputStream和outPutStream都准备就绪。其实在这种状态下就已经可以开始读写了。
3.5 CallServerInterceptor
这里已经连上了服务器,可以像操作本地文件一样读写数据了,当然要在遵守http规范的前提下。
public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain)chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection)realChain.connection();
Request request = realChain.request();
//可以看到,到这一步所需要的数据都准备就绪
long sentRequestMillis = System.currentTimeMillis();
httpCodec.writeRequestHeaders(request); //开始写数据
Builder responseBuilder = null;
if(HttpMethod.permitsRequestBody(request.method()) && request.body() != null) { //这里面是跟POST相关的
if("100-continue".equalsIgnoreCase(request.header("Expect"))) {
httpCodec.flushRequest();
responseBuilder = httpCodec.readResponseHeaders(true);
}
if(responseBuilder == null) {
Sink requestBodyOut = httpCodec.createRequestBody(request, request.body().contentLength());
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
request.body().writeTo(bufferedRequestBody); //这里就是Okio发挥高效的地方
bufferedRequestBody.close();
} else if(!connection.isMultiplexed()) {
streamAllocation.noNewStreams();
}
}
httpCodec.finishRequest(); //到这里,client的数据全部写完并且发送给服务器,服务器开始干活。
if(responseBuilder == null) {
responseBuilder = httpCodec.readResponseHeaders(false); //开始从Socket里面读取数据
}
Response response = responseBuilder.request(request).handshake(streamAllocation.connection().handshake()).sentRequestAtMillis(sentRequestMillis).receivedResponseAtMillis(System.currentTimeMillis()).build();
int code = response.code();
if(this.forWebSocket && code == 101) {
response = response.newBuilder().body(Util.EMPTY_RESPONSE).build();
} else {
response = response.newBuilder().body(httpCodec.openResponseBody(response)).build();
}
if("close".equalsIgnoreCase(response.request().header("Connection")) || "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
if((code == 204 || code == 205) && response.body().contentLength() > 0L) {
throw new ProtocolException("HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
} else {
return response;
}
}
这里面就是一步步的开始写数据了。这里再借用下百度,chrome按下F12,打开百度首页,看下request的raw header
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
DNT: 1
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4
Cookie: PSTM=122178321; BIDUPSID=CF3243290400VSDG52B3859AD4AEC2; BAIDUID=5176CC0A23DB1F3423426454DRTG5EC8:FG=1; MCITY=-%3A; BD_HOME=0; H_PS_PSSID=1428_24320_20930; BD_UPN=1223214323
看下httpCodec.writeRequestHeaders(request)的实现,就会发现真的是这么一行一行的写的
例如RequestLine.java
public static String get(Request request, Type proxyType) {
StringBuilder result = new StringBuilder();
result.append(request.method()); // GET
result.append(' '); //空格
if(includeAuthorityInRequestLine(request, proxyType)) {
result.append(request.url());
} else {
result.append(requestPath(request.url())); //我们访问的是百度首页,当然是'/'这个Index啦
}
result.append(" HTTP/1.1"); //是不是和上面一模一样
return result.toString();
}
接下来轮到Http1Codec.class
public void writeRequest(Headers headers, String requestLine) throws IOException {
if(this.state != 0) {
throw new IllegalStateException("state: " + this.state);
} else {
this.sink.writeUtf8(requestLine).writeUtf8("\r\n"); //这是第一行,写完了加上换行符
int i = 0;
for(int size = headers.size(); i < size; ++i) {
this.sink.writeUtf8(headers.name(i)).writeUtf8(": ").writeUtf8(headers.value(i)).writeUtf8("\r\n"); //一个header写完就写一个换行符
}
this.sink.writeUtf8("\r\n");
this.state = 1;
}
}
读取Response的顺序和写Request相反,不再赘述。
4.结语
这里只是针对OkHttp发起的一个最简单同步的网络请求进行了分析。
关于异步请求再说两句:本质上不过是包装了一个回调,丢到线程池里面,相比整个Http请求,实在是不值一提。来看下这个线程池
- new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
照说jdk不推荐这么创建线程池,一般用jdk封装好的CachedThreadPool,FixedThreadPool等等,但想必这样做也是不为了造成过大的系统开销吧。debug的时候如果看到OkHttp Dispatcher这条线程,应该明白是为什么了吧。另外,Okio会引入一条名为Okio WatchDog的线程,这跟Okio的AsyncTimeOut有关。时间关系(已经是夜里12点了),不打算研究了。
OkHttp总量过于庞大,很多方面,包括spdy,webSocket,RouterDatabase,DNS,网络执行周期触发回调,http2,http协议,太多太多,再研究一天也看不完。
拎出来几个比较重要的点吧:
- Okio放在最前面,就是为了说明在网络请求这样对于io性能要求高的场合,okio避免了memory allocation和不必要的缓存复制。
- OkHttpClient应该是对标apache的HttpClient的,后者不清楚。
- 底层还是调用操作系统的Socket接口,从这个角度来看,Retrofit只是一个Util,包括线程调度都是用的OkHttp的线程池;Volley我记得默认是4条NetWorkDispatcher和一个CacheDispatcher和一个ContentDelivery。
- 不推荐创建多个OkHttpClient,真想创建多个的话,用newBuilder(浅复制)就好了嘛。
- 网上说Picaso内部的cache其实就是OkHttp的cache,不愧square全家桶系列
- 和Retrofit一样,也是用的Builder模式,提供了极大的自定义空间
- Interceptor,广受业界好评的责任链模式
写于2017年7月23日0:29
update
OkHttp拦截器里面能不能把请求取消掉? 结论几乎是否
do-we-have-any-possibility-to-stop-request-in-okhttp-interceptor
随便挑一个interceptor出来,上游传递下来的chain只能获取到Request,看了下,request并没有一个cancel的方法。真要cancel的话,得去OkHttpClient那边去cancel,这里并不能获得。就算你全局获得一个Client,这里还得返回一个Response。看了下proceed方法,如果返回null的话,会主动抛一个空指针出来的。
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
cancel ongoing request
Cancelling async request by tag
//比如说一个request发出去的时候是这样的:
Request request = new Request.Builder().
url(url).tag("this-tag").build;
//这里面就是从dispatcher记录的当前正在运行和还没有开始执行的request中一个个去找。
public void cancel(OkHttpClient client, Object tag) {
for (Call call : client.dispatcher().queuedCalls()) {
if (tag.equals(call.request().tag())) call.cancel();
}
for (Call call : client.dispatcher().runningCalls()) {
if (tag.equals(call.request().tag())) call.cancel();
}
}
瞅了下call.cancel的实现,其实是对RealCall里面的成员变量RetryAndFollowUpInterceptor调用了cancel方法(再往底层就是socket.close)
这种自己主动取消的错误的 java.net.SocketException: Socket closed
超时的错误是 java.net.SocketTimeoutException
网络出错的错误是java.net.ConnectException: Failed to connect to xxxxx
动态调节timeout,也就是说随时可以修改网络请求的timeout
RealInterceptorChain.java中有这么三个方法,
Interceptor.Chain withConnectTimeout(int timeout, TimeUnit unit)
Interceptor.Chain withReadTimeout(int timeout, TimeUnit unit)
Interceptor.Chain withWriteTimeout(int timeout, TimeUnit unit)
@Test public void chainWithReadTimeout() throws Exception {
Interceptor interceptor1 = new Interceptor() {
@Override public Response intercept(Chain chainA) throws IOException {
assertEquals(5000, chainA.readTimeoutMillis());
//if 网络较差。。。
Chain chainB = chainA.withReadTimeout(100, TimeUnit.MILLISECONDS);
assertEquals(100, chainB.readTimeoutMillis());
return chainB.proceed(chainA.request());
}
};
}
所以完全可以在网络条件较差的时候修改后续的网络请求的timeout
设计模式
当一个网络请求发出时,需要经过应用层->传输层->网络层->连接层->物理层
收到响应后正好反过来,物理层->连接层->网络层->传输层->应用层
在请求经过各层时,由每层轮流处理.每层都可以对请求或响应进行处理.并可以中断链接,以自身为终点返回响应