OkHttp作者Jesse Wilson在2016 Droidcon NYC上作了一篇关于编码的演讲,十分有趣。对于了解计算机基础非常有用,结合着写一些关于这方面的笔记。
1.重新学习Java基本数据类型
基本数据类型之间的转换
初学java的时候都说没必要记住各种基本数据类型的大小范围。这里补上一些:
这些范围都是闭区间
byte:8位,最大存储数据量是255,存放的数据范围是[-128,127]间, singed。
short:16位,最大数据存储量是65536,数据范围是[-32768~32767]之间,signed。
int(整数):32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。[-2^31, 2^31-1],singed。
long(长整数):64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。[-2^63,2^63-1],signed。
float(单精度数):32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。unsigned。//这个范围只是正数部分的
double(双精度数):64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。unsigned。 //这个范围是正数部分的
boolean:只有true和false两个取值。
char:16位,存储Unicode码,用单引号赋值。
这个表的顺序是有道理的,byte->short->int->long这类表示的都是整数(不带小数点的);
float->double这类表示的都是浮点数(计算机里没有小数点,都是用类似科学计数法来表示的);
后面这俩比较特殊:
boolean只有两个值;
char专门用来表示Unicode码,最小值是0,最大值是65535(2^16-1);
- (这个范围是严格限定的,比如byte a = 127都没问题,byte a = 128 立马编译有问题。)
另外,char是为数不多的可以在java IDE里面像python一样写单引号的机会:
char c = ‘1’ // ok
char c = ‘12’//错误
char c = 12 //正确
当一个较大的数和一个较小的数在一块运算的时候,系统会自动将较小的数转换成较大的数,再进行运算。这里的大小指的是基本类型范围的大小
所以(byte、short、char) -> int -> long -> float -> double这么从小往大转是没有问题的。编译器自动转,所以经常不会被察觉。
byte、short、char这三个是平级的,相互转换也行。
试了下,
byte b = 3;
char c = '2';
short s = 23;
s = b; //只有byte往上转short是自动的
b = (byte) s;
s = (short) c;
c = (char) s;
b = (byte) c;
c = (char) b;
强转就意味着可能的精度损失。
所以除去boolean以外:
- char
- byte,short,int,long
- float,double
可以分成这三类,从小往大转没问题,同一类从小到大转没问题。
具体到实际操作上:
- char->byte->short->int->long->float->double
- 有一个操作数是long,结果是long
- 有一个操作数是float,结果是float
- 有一个操作数是double,结果是double
- long l = 424323L ,后面的L要大写。
- 这些整数都是没办法表示一个小数的,要用float或者double,后面加上f(F)或者L。
- char(16位),能表示的范围大小和short一样,是用单引号括起来的一个字符(可以是中文字符),两个字符不行。
- char的原理就是转成int,根据unicode编码找到对应的符号并显示出来。
- 两个char相加,就是转成int之后两个int相加
- double类型后面可以不写D
- float后面写f或者F都一样
2. Java中注意的点
java编译器将源代码编译位字节码时,会用int来表示boolean(非零表示真)
byte,short,int,long这些都是有符号的整数,八进制数以0开头,十六进制数字以0x开头
java7 开始 ,可以直接在代码里写二进制数,例如:
205 = 0b110_1101
3. Encoding解释
- hexadecimal 十六进制
- Decimal 十进制
- Octal 八进制
3.1 用二进制表示(0,1)任何文字的能力
数据的发送方和接收方对传输数据的结构类型达成一致,即(Encoding)。
8 bit = 1 Byte (为什么是8,据说60年代是6),8bit能够表达的范围也就是2^8 = 0-256.
1967年,ASCII码诞生,即American Standard Code for Information Interchange,即将Byte转成文字的一张表。ASCII只用了7个bits,原因是当时硬件很贵。所以就能够表示128个字符。随便找了下这张表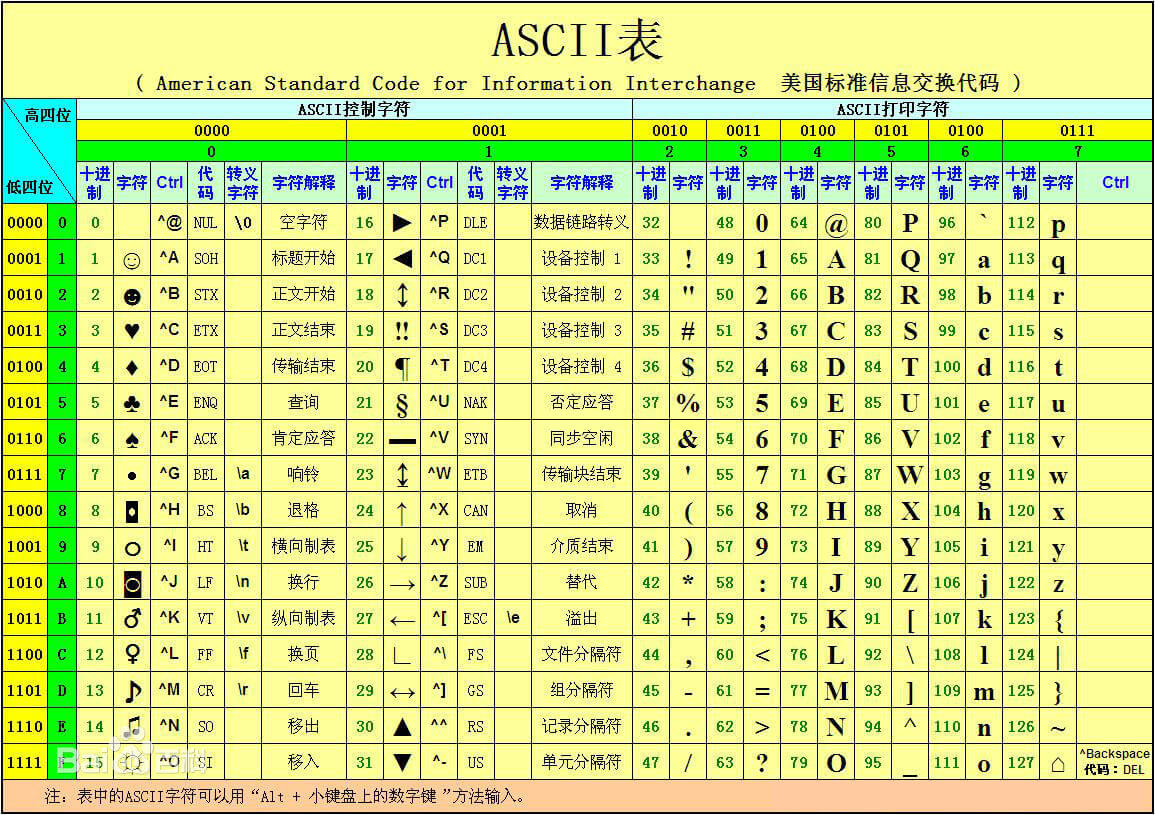
例如0表示NULL, 65表示A(大写),93表示标点符号”]”。
举例:单词Donut的每一个字母对应的ASCII分别是:
十进制 :68 111 110 117 116
二进制: 01000100 01101111 01101110 01110101 01110100
所以这么发送出去,接收者就知道是Donut了
3.2 可是128个字符不足以表示世界上所有的文字
Charset 字符集
1991年出现Unicode,用于表示所有的字符,所有语言的每一个字符都能有一个唯一的id(数字)。为了能够表达这么大的一个范围,所以得多用点内存,于是UTF-16(16-bit Unicode Transformation Format)出现了,每一个字符都得用2bytes来表示。至于这张表的范围,2^16 = 65536(好熟悉的数字),这也就是java的char类型的来源,char的定义就是16位Unicode字符。
这样做有一个显然的缺陷。
Unicode是ASCII的超集,D在ASCII中只要 01000100,在Unicode中却要在前面补上毫无意义的8个0,浪费了空间。(一般情况下,ASCII编码是1个字节,而Unicode编码通常是2个字节)Unicode的不同版本和平面(wiki上说2018年最新版的unicode已经收纳了15万个字符)
Unicode目前普遍采用的是UCS-2,用两个字节表示一个字符,那么最多能表示2的16次方,也就是65536个字了。(15万个字符怎么来的:65536个放在U+0000到U+FFFF,剩下的字符都放在辅助平面(缩写SMP),码点范围从U+010000一直到U+10FFFF。)Unicode只有一个字符集,中、日、韩的三种文字占用了Unicode中0x3000到0x9FFF的部分
Unicode目前普遍采用的是UCS-2,它用两个字节来编码一个字符, 比如汉字”经”的编码是0x7ECF,注意字符编码一般用十六进制来 表示,为了与十进制区分,十六进制以0x开头,0x7ECF转换成十进制 就是32463,UCS-2用两个字节来编码字符,两个字节就是16位二进制, 2的16次方等于65536,所以UCS-2最多能编码65536个字符。 编码从0到127的字符与ASCII编码的字符一样,比如字母”a”的Unicode 编码是0x0061,十进制是97,而”a”的ASCII编码是0x61,十进制也是97, 对于汉字的编码,事实上Unicode对汉字支持不怎么好,这也是没办法的, 简体和繁体总共有六七万个汉字,而UCS-2最多能表示65536个,才六万 多个,所以Unicode只能排除一些几乎不用的汉字,好在常用的简体汉字 也不过七千多个,为了能表示所有汉字,Unicode也有UCS-4规范,就是用 4个字节来编码字符,不过现在普遍采用的还是UCS-2,只用两个字节来 编码
在wiki里面是这么写的:
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面(英文:Basic Multilingual Plane,简写BMP。又称为“零号平面”、plane 0)里的所有字符,要用四个数字(即两个char,16bit ,例如U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五个或六个数字。
所以一个正儿八经的Unicode 的写法是
U+4AE0
春节这俩字,查表
U+6625 U+8282
浏览器里涉及编码的函数有三个:
escape(废弃,不要用)
encodeURI() //输出utf-8格式,并在每个字节前加上%
encodeURIComponent() //对uri的组成部分进行编码,同时在每个字节前面加上%,但是一些encodeURI不编码的字符,比如“/:#”,encodeURIComponent也编码了,encodeURIComponent不管页面编码是什么,统一返回utf-8
实测如下(春节的对应unicode字符集是0x6625 0x8282,用utf-8表示的话应该是)
escape(“春节”)
“%u6625%u8282” //和上面查表的结果一致,这里面的数字是16进制
encodeURI(“春节”)
“%E6%98%A5%E8%8A%82” //也是16进制
encodeURIComponent(‘春节’)
“%E6%98%A5%E8%8A%82”
许多在线utf-8转换网站粘贴进去的效果是这样的
春节 -> utf-8
春节 ##感觉这还只是unicode啊,
这个奇怪的&#x表示后面跟着的是16进制。「&#」开头的后接十进制数字,以「&#x」开头的后接十六进制数字
python3中测试
'春节'.encode('utf-8')
b'\xe6\x98\xa5\xe8\x8a\x82' ##和上面那个encodeURIComponent的方法的结果是不是一样一样的。
b'\xe6\x98\xa5\xe8\x8a\x82'.decode('utf-8')
'春节'
b'\u6625\u8282'.decode('unicode-escape')
python3里面这些\x和\u是这样的
在bytes中,无法显示为ASCII字符的字节,用\x##显示,\u是unicode的转义字符,就是说这后面跟的都是字符的十六进制的unicode表示形式。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:x = b’ABC’
下面的方法可以获得汉字的unicode值和utf-8编码
##utf-8编码
>>> u'春节'.encode('utf-8') ## unicode转utf-8,解码就是decode了
'\xe6\x98\xa5\xe8\x8a\x82'
## unicode字符码
>>> u'春节'
u'\u6625\u8282' ## 春节的Unicode就是U+6625 U+8282
`
- 但还是没法表示一些特殊字符,例如Emoji,Dount Emoji的id是127,849。原因是90年代的设计者没有想到今天会出这么多emoji。解决办法是”surrogate pairs”。下面解释:
java的String其实不过是一个char Array的wrapper,如果在ide里面看的话,String里面的char[]每个数字都代表这个位置的Unicode id。所以经常在IDE里debu看到String里面有char[],1=”67”;2=“79”。。。这种东西,其实也就是这个String(字符串)中对应位置的字符的unicode码。对于Emoji,会用两个char来表示。如何确定相邻的两个字符应该用来表示一个Emoji而是两个独立的字符?
去看Emoji的Unicode表的话,这四个byte连在一起一般长这样: - \xF0\x9F\x98\x81
- \xF0\x9F\x98\x82
- \xF0\x9F\x98\x83
- \xF0\x9F\x98\x84
中间那个\x9F\x98就是surrogate pairs的标志
所以,要认识到char本身还是不足以表示所有的字符
这样的代码要是拿来打印Emoji,只会讲原本4byte的Emoji拆成2个char,所以就在console里面看到一些乱码。
String s = "一些包含Emoji的文字"
for(int i =0 ,size = s.length();i<size;i++){
char c = s.charAt(i);
System.out.println("The Character at %d is '%c'%n",i,c);
}
处理emoji的正则,主要是python
提供了一个扫描出emoji的正则
def test_emoji():
try:
# Wide UCS-4 build
myre = re.compile(u'['
u'\U0001F300-\U0001F64F'
u'\U0001F680-\U0001F6FF'
u'\u2600-\u2B55]+',
re.UNICODE)
except re.error:
# Narrow UCS-2 build
myre = re.compile(u'('
u'\ud83c[\udf00-\udfff]|'
u'\ud83d[\udc00-\ude4f\ude80-\udeff]|'
u'[\u2600-\u2B55])+',
re.UNICODE)
sss = u'I have a dog \U0001f436 . You have a cat \U0001f431 ! I smile \U0001f601 to you!'
print(sss)
print(myre.sub('[Emoji]', sss)) # 替换字符串中的Emoji
print(myre.findall(sss)) # 找出字符串中的Emoji
正确的做法是:
String emoji = "嘿嘿\uD83D\uDC37咦丶恸";
System.out.println(emoji);
for(int i =0 ,size = emoji.length();i<size;){
int c = emoji.codePointAt(i);
System.out.println(String.format("The Character at %d is '%c'%n", i,c));
i+=Character.charCount(c);//正确识别char数量
}
输出:
嘿嘿🐷咦丶恸
The Character at 0 is ‘嘿’
The Character at 1 is ‘嘿’
The Character at 2 is ‘🐷’
The Character at 4 is ‘咦’
The Character at 5 is ‘丶’
The Character at 6 is ‘恸’
emoji有一个特点,两个char(4个byte的第二个是3D,第三个是DC,这俩叫做surrogate pairs,当然第二个不一定是3D,而是一个范围内,具体在isHighSurrogate中)
codePointAt(int index)的实现在codePointAtImpl中,事实上就是判断位于index的这个char是否isHighSurrogate(第二个是不是3D),如果是,跟着判断isLowSurrogate(++index)(第三个是不是DC).
汉字用UTF-8编码的话,有些还是会超出两个字节的,比如“𠮷”,wiki给这货的解释。十进制是134071,已经超出两个字节(65536)了。
转成十六进制的话就是“F0 A0 AE B7”,utf-8本身就是可变长度的编码format,所以这货占了4个字节也正常。
String w = "\uD842\uDFB7"; //这个“\u”是ide自己加上去的,注意和上面的十六进制不一样,是因为utf-8前面要加一些0,1什么的
System.out.println(String.valueOf(hex)); // 134071
for (int i = 0,size = w.length(); i <size;) {
int c = w.codePointAt(i);
System.out.println(String.format("The character at %d is %c ", i, c)); //成功打印出这个汉字
i += Character.charCount(c);
}
jni中的GetStringUTFChars返回的并不是utf8 array 而是Modified UTF-8
3.3 UTF-8出现
8-bit Unicode Transformation Format于1998年出现,之前提到了2个byte表示一个字符实在太浪费了,utf-8的做法是将每个字符所需要的长度变成可变的。WIKI上UTF-8的描述
- 多数字符只用1byte,有些用到2,3个byte,Donut的Emoji用4bytes.
<=7个bit的(ASCII): 0XXXXXX (我用X表示可以被填充的空间)
<=11个bit :110XXXXX 10XXXXXX (第一个byte以110开头,后面以10开头)
<=16个bit : 1110XXXX 10XXXXXX 10XXXXXX (第一个byte以1110开头,后面跟两个10开头的bytes)
<=21个bit : 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX (第一个byte以11110开头,后面跟三个10开头的bytes)
00000000 – 0000007F: 0xxxxxxx
00000080 – 000007FF: 110xxxxx 10xxxxxx
00000800 – 0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
00010000 – 001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
现在来看看网上那些常用的中文转UTF-8工具怎么用,随便找一个找一个站长之家
输入“美” ,对应的utf-8编码是”美”,转Unicode是”\u7f8e”
查了下“美”这个字还真是“7F8E”。这里有张比较好的表格。
二进制转unicode直接粘贴到这里的转16进制就可以了。转utf-8的话,来看这个其实是15个bit。所以这样写
7F8E显然是16进制,转成十进制是32654。
转成二进制是11111111 0001110(注意只有15个bit,前面8个1)。
转utf-8的时候,从后往前往上面的XXXX里面填充
1110XXXX 10XXXXXX 10XXXXXX就变成了
1110X111 10111110 10001110(注意有一个位置还空着)
X用0补上,最终得到汉字"美"的utf-8二进制编码
11100111 10111110 10001110
读取的时候
1111 111100 01110(7f8e)
,这三个byte就代表汉字”美”。
Integer.toBinaryString提供了将一个int(十进制)转成二进制字符的方法,即给一个十进制数字,转成”01010101110101”这样的String,方便看懂。
即转成一大堆”0101010110”
来试一下,看怎么获得这些”01010101110101”.
public static void main(String[] args) {
String s = "美";
char[] array = s.toCharArray();
for (int i = 0,size = array.length; i < size; i++) {
System.out.println(array[i]);
System.out.println(Integer.toBinaryString(array[i]));
}
}
//输出 111111110001110
古人诚不我欺也
反过来,用一大堆”0101010111010”也能在java代码里写一个汉字出来
char c = 0b111111110001110;
String ns = new String(new char[]{c});
System.out.println(ns);
0b是java 1.7开始可以使用的用来直接在代码里写二进制的方式。
so if you want improve the cooleness of your code…
当然java早就准备好了相应的方法(二进制-八进制-十进制-十六进制)之间的互相转化
十进制转成十六进制:
String Integer.toHexString(int i)
十进制转成八进制
String Integer.toOctalString(int i)
十进制转成二进制
String Integer.toBinaryString(int i)
十六进制转成十进制
Integer.valueOf("FFFF",16).toString() //不能处理带前缀的情况 0x
八进制转成十进制
Integer.valueOf("76",8).toString() //前缀0可以被处理
二进制转十进制
Integer.valueOf("0101",2).toString()
String还有一个getByte(Charset)方法,可以传各种charset进去,i/o强调的是读写使用的都是相同的编码,否则就会出现乱码。
4.接下来讲颜色
颜色就是RGB的组合,屏幕中每一个像素都是由三个subPixel组成的(分别是红绿蓝),所以在ps里面经常会碰到255,XXX,XXX这种东西。
0,0,0代表全黑,255,255,255(0-256也就是一个byte能够表达的范围)代表纯白。其他的颜色都是这三种颜色的组合,所以用三个byte就能表达一种颜色。
所以经常在java代码里看到:
view.setBackgroundColor(Color.parseColor("#87CEFA"));//三个bytes
//或者
Color.RED
//还有更好玩的
tv.setTextColor(Color.rgb(255, 255, 255));
//"#XX XX XX" 十六进制,256的范围,只需要2位数字就好了,所以总是看到00,01,10,...ff这样
在xml里面是这样的
<?xml version="1.0" encoding="utf-8"?>
<resources>
<color name="wl_blue">#2878ff</color>
<color name="wl_gray">#c1c1c1</color>
<color name="text_color">#434343</color>
</resources>
只不过少写了0x而已
关于十六进制,多说一点
- Colors: #ffffff
- URL escaping:http://example.com/?q=hello%20world
- Unicode code points: U+2020
- ipv6地址: 2001∶0d02∶0000∶0000∶0014∶0000∶0000∶0095
都是十六进制(Dexadecimal)的应用
5.有了颜色就有了图片
3个小像素组成一个像素,屏幕上无数个像素(颜色的点,每个像素大小为3bytes)组成了图片,图片只是一个颜色的2维数组(数组的每个元素是一个颜色)。
那么一张6464pixel的图标大小为,64643 = 12 288bytes,现在的屏幕动辄百万像素,19801080的图片,大小是198010803 = 6.4MB。现在明白Android上图片为什么这么容易oom了吧。这还只是rgb,其实正规图片应该还有一个Alpha,即ARGB,好了,这下占用了192010804 = 8MB。所以Android在Bitmap里面提供了一些选项:
BitMap.config.ALPAH_8 :只存储透明度,不存储颜色信息
BitMap.config.ARGB_4444(Deprecated) :Each pixel is stored on 2 bytes. (节省了一半)
BitMap.config.ARGB_8888 : Each pixel is stored on 4 bytes. Each channel (RGB and alpha for translucency) is stored with 8 bits of precision (256 possible values.) This configuration is very flexible and offers the best quality. It should be used whenever possible.这也就是上面提到的一个像素三个小像素外加一个透明度的算法。
Bitmap.Config RGB_565: Each pixel is stored on 2 bytes and only the RGB channels are encoded。(能这么省是因为这里面用5bit表示red,6bit表示green,5bit表示blue,这个划分似乎是UI行业的标准,用了一些近似算法。所以经常看到有人拿着两张ARGB_8888和RGB_565的图片来比较,然后批判RGB_565颜色不准)。RBG_565本来就不是冲着颜色准确去的。其实还有RBG_232这种更加不准确的。
日常开发都是用的ARGB_8888,一个像素要用4bytes内存,所以bitmap真的非常耗内存。
公式在cpp源码中
if (willScale && decodeMode != SkImageDecoder::kDecodeBounds_Mode) {
scaledWidth = int(scaledWidth * scale + 0.5f);
scaledHeight = int(scaledHeight * scale + 0.5f);
}
最终的大小就是
scaledWidthscaledHeight4
一张522*686的PNG 图片,我把它放到 drawable-xxhdpi 目录下,在三星s6上加载,占用内存2547360B,其中 density 对应 xxhdpi 为480,targetDensity 对应三星s6的密度为640:
(实际长/xxxhdpi文件夹对应的值) 手机dpi (实际宽/xxxhdpi文件夹对应的值) 4
522/480 640 686/480 640 * 4 = 2546432B(同样一张图片,放在xxxhdpi占用内存< 放在xxhdpi < 放在xhdpi,经验之谈,放在xxxhdpi是一种降低内存占用的方式)
找到了cpp层调用java层的gVMRuntime_newNonMovableArray方法:
至少到了7.0还是通过jni把像素这个数据大户放到了java heap上面
android::Bitmap* GraphicsJNI::allocateJavaPixelRef(JNIEnv* env, SkBitmap* bitmap,
SkColorTable* ctable) {
jbyteArray arrayObj = (jbyteArray) env->CallObjectMethod(gVMRuntime,
gVMRuntime_newNonMovableArray,
gByte_class, size);
return wrapper;
}
Android Bitmap变迁与原理解析(4.x-8.x)谈到了这一块的分配非常乱
A Bitmap is just an interface to some pixel data. The pixels may be allocated by Bitmap itself when you are directly creating one, or it may be pointing to pixels it doesn’t own such as what internally happens to hook a Canvas up to a Surface for drawing. (A Bitmap is created and pointed to the current drawing buffer of the Surface.)
看下java层的bitmap的成员变量,并没有什么特别大的数组,所以真正的像素数据的存储不是放在bitmap这个对象里的。
根据懂c++人的分析,通过调用jni的CallObjectMethod来调用gVimRuntime的gVMRuntime_newNonMovableArray方法来创建一个数组,这个数组类型和长度分别用gByte_class和size表示。CallObjectMethod函数返回一个jbyteArray,此时,在Java层已经创建了一个长度为size的byte数组。
也就符合official document中说的 the pixel data is stored on the Dalvik heap along with the associated bitmap. 说法了。我的理解是,庞大的像素数据是放在java层的,因为是直接gVimRuntime进行调用gVMRuntime_newNonMovableArray来创建的,并不会对开发者暴露这个数组的直接引用(直接乱改也不好吧),而是使用bitmap这个对象进行间接操作。
官方文档其实也更新了:
From Android 3.0 (API level 11) through Android 7.1 (API level 25), the pixel data is stored on the Dalvik heap along with the associated bitmap. In Android 8.0 (API level 26), and higher, the bitmap pixel data is stored in the native heap.
6.来看一张图片是怎么写出来的(在文件系统中)
我这里直接把Jesse Wilson的代码复制过来,大意就是写一个bmp文件的方法,先写文件头,然后从那个int[][]中读取数组,写进一个文件,也就得到一个.bmp文件了。文件就是这么写的。
public final class Bitmap {
private final int[][] pixels;
public Bitmap(int[][] pixels) {
this.pixels = pixels;
}
/** https://en.wikipedia.org/wiki/BMP_file_format */
public void encode(BufferedSink sink) throws IOException {
int height = pixels.length;
int width = pixels[0].length;
int bytesPerPixel = 3;
int rowByteCountWithoutPadding = (bytesPerPixel * width);
int rowByteCount = ((rowByteCountWithoutPadding + 3) / 4) * 4;
int pixelDataSize = rowByteCount * height;
int bmpHeaderSize = 14;
int dibHeaderSize = 40;
// BMP Header
sink.writeUtf8("BM"); // ID.
sink.writeIntLe(bmpHeaderSize + dibHeaderSize + pixelDataSize); // File size.
sink.writeShortLe(0); // Unused.
sink.writeShortLe(0); // Unused.
sink.writeIntLe(bmpHeaderSize + dibHeaderSize); // Offset of pixel data.
// DIB Header
sink.writeIntLe(dibHeaderSize);
sink.writeIntLe(width);
sink.writeIntLe(height);
sink.writeShortLe(1); // Color plane count.
sink.writeShortLe(bytesPerPixel * Byte.SIZE);
sink.writeIntLe(0); // No compression.
sink.writeIntLe(16); // Size of bitmap data including padding.
sink.writeIntLe(2835); // Horizontal print resolution in pixels/meter. (72 dpi).
sink.writeIntLe(2835); // Vertical print resolution in pixels/meter. (72 dpi).
sink.writeIntLe(0); // Palette color count.
sink.writeIntLe(0); // 0 important colors.
// Pixel data.
for (int y = height - 1; y >= 0; y--) {
int[] row = pixels[y];
for (int x = 0; x < width; x++) {
int pixel = row[x];
sink.writeByte((pixel & 0x0000ff)); // Blue.
sink.writeByte((pixel & 0x00ff00) >> 8); // Green.
sink.writeByte((pixel & 0xff0000) >> 16); // Red.
}
// Padding for 4-byte alignment.
for (int p = rowByteCountWithoutPadding; p < rowByteCount; p++) {
sink.writeByte(0);
}
}
}
public void encodeToFile(File file) throws IOException
try (BufferedSink sink = Okio.buffer(Okio.sink(file))) {
encode(sink);
}
}
这里没有考虑压缩算法。这里面还有Big Ending和Small Ending的处理。
Big Ending: 拿32bit ,一次读8bit,从左到右
Little Ending: 拿32bit ,一次读8bit,从右到左读
7.从json到protoBuffer以及http2
一般我们看到的json是这样的
{
"price": 14,
"gender": true,
"height": 1.65,
"grade": null,
"time": ,"2016-09-30T18:30:00Z"
}
注意那个事件戳,时间戳本可以用long(8bytes)表示,这上面的String的每个字符都在英文或者阿拉伯数字,所以在ASCII内,所以一个字符按照utf-8编码的话也就1byte,一个个数下来也有二十多个bytes。从8bytes到二十多个bytes,浪费了一半多的bits。数据量越大,编码越慢,传输越慢,解码越慢。
来看protocolBuffer,protocolBuffer一般长这样,每一个field都有一个独一无二的tag.
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
以 optional string email = 3 为例,ProtocolBuffer定义了一个length mode(enum,int32,int64是000,fixed64是001,String,message是010),拿一个byte出来,先把后面三位填上010,即XXXXX010,然后把3在前面,即00011010,一共只用了一个byte就把String email这句话表示出来了。即protobuffer只需一个byte就能表示key,同样的key,json要12byte(utf-8下一个字母一个byte)。value也是一样,转成hex的形式。
印象中http2也是用数字来表示header key的,类似的节省数据的道理。
json是有rfc规范rfc4627的
JSON text SHALL be encoded in Unicode. The default encoding is UTF-8.
8. 补充
8.1 Big-ending和Little-endian这名字其实跟文学作品有关
- Notepad++可以右下角可以看到当前文件的编码方式,utf-8 dom跟微软有关,最好不要用.
- Python前面写的”# -- coding: utf-8 --“跟这事有关,”#!/usr/bin/python”是用来说明脚本语言是python的
- unicode是字符集,utf-8是一种编码形式。
- 《格列夫游记》里面,吃鸡蛋先打打头还是小头详解
- 文档头部放一个BOM (用来表示该文件的字节序,BOM是FFFE或者FEFF,操作系统也就能判断是大端还是小端了)大小端的介绍
- 全角和半角跟GB2312把一些ASCII里面已有的拉丁字母又编码了一遍有关。
- GB2312 是对 ASCII 的中文扩展.在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
- 大端小端没有谁优谁劣,各自优势便是对方劣势
- 大小端的应用
- windows记事本会强行给utf-8加上bom,主要是为了兼容旧版本系统。BOM就是(“FE FF”)这么几个二进制,notepad++需要装插件才能看二进制,比较好的解释看这篇.直接用InputStream往文件里写byte数组,接着读出来,编码不对就报错。
- 很多人都有用记事本编辑代码出错的经历,所以尽量不要用windows下的记事本编辑代码。notepad++默认保存为utf-8不带bom格式,所以编辑文件没什么问题。
- 只有读取的时候,才必须区分字节序,其他情况都不用考虑。
字节序指的是多字节的数据在内存中的存放顺序
在一个32位的CPU中“字长”为32个bit,也就是4个byte。在这样的CPU中,总是以4字节对齐的方式来读取或写入内存,那么同样这4个字节的数据是以什么顺序保存在内存中的呢?例如,现在我们要向内存地址为a的地方写入数据0x0A0B0C0D,那么这4个字节分别落在哪个地址的内存上呢?这就涉及到字节序的问题了。
网络字节序:TCP/IP各层协议将字节序定义为 Big Endian,因此TCP/IP协议中使用的字节序是大端序。
主机字节序:整数在内存中存储的顺序,现在 Little Endian 比较普遍。(不同的 CPU 有不同的字节序)
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而现在比较普遍的 x86 处理器是 Little Endian
JAVA编写的程序则唯一采用 Big Endian 方式来存储数据
一般操作系统都是小端,而通讯协议是大端的。
4.1 常见CPU的字节序
Big Endian : PowerPC、IBM、Sun
Little Endian : x86、DEC
ARM既可以工作在大端模式,也可以工作在小端模式。
查看当前操作系统的字节序
```python
python3 -c 'import sys; print(repr(sys.byteorder))'
System.out.println(ByteOrder.nativeOrder());
mac和linux上都输出了
‘little’
c语言中htons函数处理了端口号字节序,将short型数据从当前主机字节序转换为网络字节序
//创建sockaddr_in结构体变量
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每个字节都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
serv_addr.sin_port = htons(1234); //端口号
常见的网络字节转换函数有:
htons():host to network short,将short类型数据从主机字节序转换为网络字节序。
ntohs():network to host short,将short类型数据从网络字节序转换为主机字节序。
htonl():host to network long,将long类型数据从主机字节序转换为网络字节序。
ntohl():network to host long,将long类型数据从网络字节序转换为主机字节序。
另外需要说明的是,sockaddr_in 中保存IP地址的成员为32位整数,而我们熟悉的是点分十进制表示法,例如 127.0.0.1,它是一个字符串,因此为了分配IP地址,需要将字符串转换为4字节整数。
inet_addr() 函数可以完成这种转换。inet_addr() 除了将字符串转换为32位整数,同时还进行网络字节序转换。
为 sockaddr_in 成员赋值时需要显式地将主机字节序转换为网络字节序,而通过 write()/send() 发送数据时TCP协议会自动转换为网络字节序(大端),不需要再调用相应的函数。
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的 0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。
因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。
大小端转化的算法在java这边是这样的参考
/**
* 将int转为低字节在前,高字节在后的byte数组 (小端)
* @param n int
* @return byte[]
*/
public static byte[] toLH(int n) {
byte[] b = new byte[4];
b[0] = (byte) (n & 0xff);
b[1] = (byte) (n >> 8 & 0xff);
b[2] = (byte) (n >> 16 & 0xff);
b[3] = (byte) (n >> 24 & 0xff); // 把高字节拿到后面
return b;
}
/**
* 将int转为高字节在前,低字节在后的byte数组 (大端)
* @param n int
* @return byte[]
*/
public static byte[] toHH(int n) {
byte[] b = new byte[4];
b[3] = (byte) (n & 0xff);
b[2] = (byte) (n >> 8 & 0xff);
b[1] = (byte) (n >> 16 & 0xff);
b[0] = (byte) (n >> 24 & 0xff);
return b;
}
public static String bytesToString(byte[] b) {
StringBuffer result = new StringBuffer("");
int length = b.length;
for (int i=0; i<length; i++) {
result.append((char)(b & 0xff));
}
return result.toString();
}
/**
* 将字符串转换为byte数组
* @param s String
* @return byte[]
*/
public static byte[] stringToBytes(String s) {
return s.getBytes();
}
c语言的转换参考
htonl() htons() 从主机字节顺序转换成网络字节顺序
ntohl() ntohs() 从网络字节顺序转换为主机字节顺序
用c语言检查当前平台大小端
{
int i = 1;
char *p = (char *)&i;
if(*p == 1)
printf("Little Endian");
else
printf("Big Endian");
}
如果是big endian的话,内存里面的存法是 ox00 ox00 ox00 ox01
如果是little endian的话,内存里存的是 ox01 ox00 ox00 ox00
union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写。
/*return 1: little-endian, return 0: big-endian*/
int checkCPUendian()
{
union
{
unsigned int a;
unsigned char b;
}c;
c.a = 1;
return (c.b == 1);
}
实现同样的功能,来看看Linux 操作系统中相关的源代码是怎么做的:
static union { char c[4]; unsigned long mylong; } endian_test = {{ 'l', '?', '?', 'b' } };
#define ENDIANNESS ((char)endian_test.mylong)
Linux 的内核作者们仅仅用一个union 变量和一个简单的宏定义就实现了一大段代码同样的功能!(如果ENDIANNESS=’l’表示系统为little endian,为’b’表示big endian)
如果只是字节流,不需要转换(因为网络的字节序都是大端,应用程序层读到的都是大端)。一般是ip地址,端口号码,传输一些整型数的参数,才需要做转换,字节流不需要。如果头部记录了大小的,那么这个记录了大小的整型数需要转换
4.2 常见文件的字节序
Adobe PS – Big Endian
BMP – Little Endian
DXF(AutoCAD) – Variable
GIF – Little Endian
JPEG – Big Endian
MacPaint – Big Endian
RTF – Little Endian
另外,Java和所有的网络通讯协议都是使用Big-Endian的编码。
### 8.2 读取一个json文件
先用BufferedSource将文件变成一个Source,再用Moshi从这个Source里面读数据
### 8.3 从一个byte[]中读取一个int或者写一个int可以这样
在com.square.tape.QueueFile中看到
```java
private static int readInt(byte[] buffer, int offset) {
return ((buffer[offset] & 0xff) << 24)
+ ((buffer[offset + 1] & 0xff) << 16)
+ ((buffer[offset + 2] & 0xff) << 8)
+ (buffer[offset + 3] & 0xff);
}
private static void writeInt(byte[] buffer, int offset, int value) {
buffer[offset] = (byte) (value >> 24);
buffer[offset + 1] = (byte) (value >> 16);
buffer[offset + 2] = (byte) (value >> 8);
buffer[offset + 3] = (byte) value;
}
一个int占据4个字节,没问题。
有一个一维整型数组int[]data保存的是一张宽为width,高为height的图片像素值信息。请写一个算法,将该图片所有的白色不透明(0xffffffff)像素点的透明度调整为50%。
final int size = data.length;
for(int i = 0; i< size; i++){
if(data[i] == 0xffffffff)
data[i] = 0x80ffffff; // ARGB_8888 一个像素占据4个bytes,A(alpha)R(red)G(green)B(blue)。所以只要改alpha就好了
}
总结
- 软件开发能够接触到的最小单位byte就是8个排在一起的可以盛放0或者1的小槽子。从60年代的ASCII到后来的utf-8再到今天的utf-8,成熟的业界标准使得计算机行业能够跨语言形成信息处理,传输,消费的统一化,同时兼顾了效率。
- 图片只是无数颜色的组合,用byte表示RGB的方式使得电子产品显示图片变为可能。
- 在数据传输中,数据传输双方可以协商采取合理的传输协议,让通信量变得小,通信速度变快。
- hexadecimal简化了写无数个01的过程,日常开发尽量写0xffffff这种形式。两个十六进制数字的组合通常代表一个byte的范围。
- 根据阮一峰的介绍,目前,Unicode的最新版本是7.0版,一共收入了109449个符号,其中的中日韩文字为74500个。可以近似认为,全世界现有的符号当中,三分之二以上来自东亚文字。
oracle文档上就这么写的
The Java programming language represents text in sequences of 16-bit code units, using the UTF-16 encoding.
java内存中字符的存储方式是utf-16,因为简单啊,不用像utf-8那样麻烦( random access cannot be done efficiently with UTF-8) 为什么java用utf-16
java最早用的是UCS-2(以为16个bit足以表达所有字符集,随着unicode的发展,发现16个也不够了),但历史上utf-16一开始是固定长度两个字节的,后面发现不够表示unicode了就改成变长的,16或者32bit.
Since 16 bits can only contain the range of characters from 0x0 to 0xFFFF, some additional complexity is used to store values above this range (0x10000 to 0x10FFFF). This is done using pairs of code units known as surrogates.
UTF-8 requires either 8, 16, 24 or 32 bits (one to four octets) to encode a Unicode character, UTF-16 requires either 16 or 32 bits to encode a character, and UTF-32 always requires 32 bits to encode a character.
Java的String内存储的字符串使用的是Unicode编码(默认使用UTF16编码),Unicode是可扩展的,不过目前大部分情况下UTF16只用到了2个字节(大多数非生僻汉字还是可以用两个byte搞定的)
public static String getRandomChar(){
char[] arr = {'一','二','三','四','五'};
return "" + arr[1] + arr[2] +arr[4];
}
public static void main(String[] args) {
String cc = getRandomChar();
System.out.println("输出的文字是" + cc);// 输出的文字是二三五
}
而在c语言中,一个字符(char)只需要1个字节
参考
- Jesse Wilson | Decoding the Secrets of Binary Data
- 深入分析 Java 中的中文编码问题IBM出品,非常好,甚至告诉你什么情况下会出现哪种奇怪的显示符号
- emoji complete list