http建立在tcp,ip基础上,tcp协议的可靠性意味着每次http请求都会分解为多次ip请求。很多出于book keeping的东西占用了实际发送数据的相当一部分,具体占用多少。由此顺便展开到http和tcp的基本关系。
大部分基于Hadi在2016年的演讲
1. Http的几个概念
1.1 bandwidth和latency的概念
bandwidth是指数据传输的速度上限(运营商设置),latency是物理距离限制的信号传递到达的时间(中美之间的延迟一般180ms左右,这是物理距离决定的)。
1.2 为什么http1.1差劲
这是由于latency决定的,跟bandwidth无关。假设客户端和服务器之间存在一定带宽限制,随着带宽上限的提高,两者之间的传输速度趋于平衡。只有在路不够宽的时候,路的宽度才会成为交通的阻碍,如果路足够宽,那么通信双方的通信速度只和两者之间的物理距离有关。
要命的是,每一次连接都受到延迟影响。
1.3 现代网站的复杂化程度使得网络请求越来越频繁
http(超文本传输协议),最初设计的时候确实只需要传输一些固定的文字,可能只要一条连接就够了。随着现在网页越来越复杂,打开一个网页,在chrome里面能看到一瞬间请求的资源多达几十个甚至上百个。想象下,每条连接都会受到latency的影响,浪费的时间成倍数增长。webpagetest可以展示加载一个页面的过程中都发起了哪些请求,并以waterfall view的形式展示出来。比直接在chrome里面看更加直观。
1.4 ISO OSI Layer一共七层
- Application (Http在这一层,但人们习惯把它当做第四层)
- Presentation
- Session
- Transport (Tcp在这)
- Network
- Link
- Physical
Http本身是OK的,tcp为了确保可靠性,建立连接要三次握手,断开连接要四次挥手。真正有用的数据传输只在这两者之间。每次发起请求,都需要带上这些必要的数据传输。
这里面还有Handshake,客户端每收到一个包,都要向服务端发Acknowledgement(ACK)。
还有Flow Control(两端之间传输数据,实现并不知道两者之间的道路有多宽,所以先传100byte试试,一切ok在提到200byte,接着提到500byte,万一出现问题,退回到200byte,这就叫congestion)。
Flow Control的存在是有道理,但却使得每一条连接都得从很小的传输速度进行尝试,这就造成了延迟的增大。
1.5 HTTP 0.9 始于 1991年
0.9版本的Http还没有header,1996年的Http 1.0 加入了Header。但这种协议的设计初衷并不是为了现在这种一个网页带上300个请求的事实而设计的。 1999年,http 1.1 加入了Connection close(默认是Keep-Alive)。Keep-Alive的好处是Tcp连接不会在一个http请求结束之后就断开,也就没有三次握手这种东西了。
1.6 一些前人总结的优化技巧
- Sigle connection (/index.html;style.css全都放在一个连接里面)
- Pipelining (一次性请求index.html以及style.css,这些东西全都放在一个请求里面)。这种方式的问题叫做 Head-of-line Blocking,由于tcp是可靠的协议,所以必须得等第一个请求的response回来,后续的请求才能执行。所以很多浏览器后来都放弃了对这种技术的支持。
- 于是人们开始一次性发出多个tcp请求。客户端能同时向一个host(不同host之间不影响)发起的请求最多6(不同浏览器数量不同)到8个。这么干的原因一方面是客户端自我保护,另一方面也是为了保护服务器不至于崩溃。具体在知乎上有讨论
所以我们经常看到知乎把api数据放在zhihu.com上,图片放在zhimg.com,统计放在zhstatic.com上。有时候还会有pic2.zhimg.com,pic3.zhimg.com。。。等等这些,还不是为了加快网页加载速度。(这就叫domain Sharding),这么干也有坏处,More DNS lookups。找dns花的时间多了。 - Inline resources
直接把图片放在html里面传回来,这造成缓存失效。还有编码的问题 - Concatenating and Spriting resources
Concatenating是把所有的js文件塞在一个大的js里面返回,这也造成缓存失效,处理缓慢等问题。
Spriting是把一大堆图片放在一整张图片里面,通过复杂的css选择其中的图片。
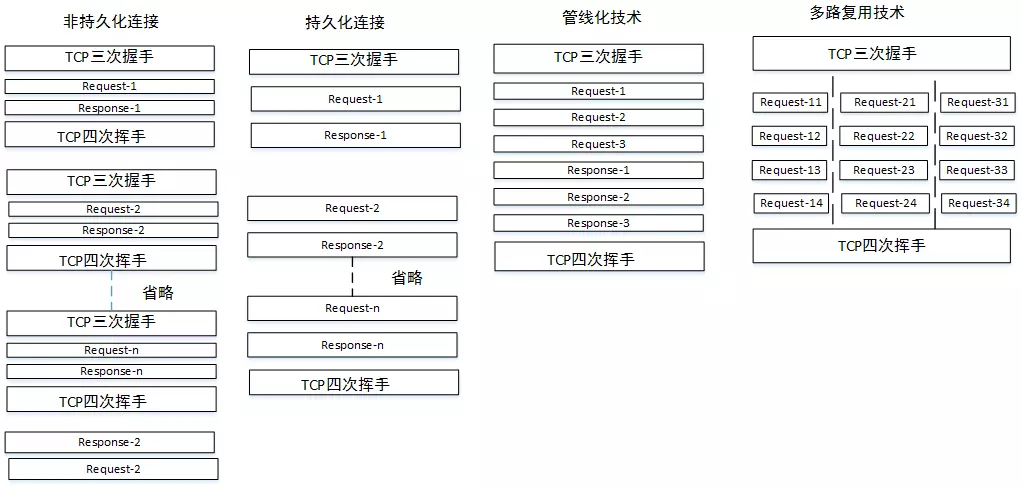 管道和多路复用
管道和多路复用
2. http2的开始
Http有点像一种谈话式的协议,但tcp并不是。http并没有什么错,慢就慢在tcp
http2的一些要点如下
- Binary Communication(http1.X 就是往socket里面写文字,h2直接写binary, 解析binary的速度要比解析文字快)
- Compression and optimization techniques(GZip没法压header,h2压缩了header)
- No change in HTTP semantics(主要是为了backward compatibility,GET,POST这些都没变)
- Not compatible with HTTP1.X but can be used ontop of it
2.1 SPDY
谷歌设计了SPDY,h2建立在SPDY的基础上,google已经废弃了SPDY,据说是为了给h2让路。
2.2 h2过程
h2传输的是Binary Frame,这里面包括HEADER FRAME和DATA FRAME, request的body和response的body都通过DATA FRAME传输。
client发起一个请求,header里面包括(Upgrade:2c),一切OK的话,服务器返回一个status code 101(switching Protocol)。
在response header里面返回一个Upgrade: h2c。
2.3 TLS ,SSL
用于两点间传输binary数据
TLS(Transport Layer Security),SSL(Secure Sockets Layer)
ALPN(Application Level Protcol Negotitation)
2.4 数据传输的模型
h2只有一条connection,里面有多个STREAM,STREAM里面包括了Request的HEADER FRAME和DATA FRAME以及Response的HEADER FRAME和DATA FRAME。
FRAME里面有length,Type,Flags,ID(有了ID就能有sequence,也就能multiplexing,多路复用)以及Payload(数据)。
FRAME TYPE有很多种,DATA,HEADER,WINDOW_UPDATE,SETTING,GOAWAY,这些在okhttp里面都能看到.
用WireShark可以查看
h2为什么快,Multiplexing,多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息
2.5 Header Compression
本来GZip是不能压缩Header的,h2使用HPACK(很复杂的协议),讲header(无非是键值对)中的key,value映射一份表,所以每一次发起请求,h2会将那些header变成数字,同时,只会发送改变了的header。(应用层无需关心,十分复杂)
2.6 Streams可以设置优先级
都是在一条Connection中发送出去,开发者可以设置,例如,js优先级高点,image优先级低一点。
2.7 Flow Control
- Multiplexing requires ability of flow control
- WINDOW_UPDATE
2.8 Server Push
客户端请求一个网页如 index.html,服务器会觉得,客户端很有可能还想要style.css和script.js。于是顺带着也给丢过来了。server push大致如此。
这样的好处就是,client无需发起请求,省了流量。同时,client还可以说GO_AWAY,也就是拒绝SERVER的push。
3.现状
现在很多网站已经支持了h2,twitter好像就是。一个很简单的方法就是看chrome里面的network,h2只有一条线。
服务器这边,Ngnix 1.9.5支持h2,Apache 2.4.12开始支持
客户端这边 Netty,OkHttp,Curl 都行
进入h2,domain sharding,Concatenation and Spriting,InLining这些techniques都没有意义了。
Update
With 100Mbit/s Ethernet, a large file transfers at 94.1Mbit/s. That’s 6% overhead.
所以本地记录的下载到的文件的速度要比运营商报告的实际带宽小一点,当然这只是一部分原因。
看看一个TCP包除了数据之外还塞了写哪些bookKeeping的东西当···时发生了什么
使用套接字
当浏览器得到了目标服务器的 IP 地址,以及 URL 中给出来端口号(http 协议默认端口号是 80, https 默认端口号是 443),它会调用系统库函数 socket ,请求一个 TCP流套接字,对应的参数是 AF_INET/AF_INET6 和 SOCK_STREAM 。
这个请求首先被交给传输层,在传输层请求被封装成 TCP segment。目标端口会被加入头部,源端口会在系统内核的动态端口范围内选取(Linux下是ip_local_port_range)
TCP segment 被送往网络层,网络层会在其中再加入一个 IP 头部,里面包含了目标服务器的IP地址以及本机的IP地址,把它封装成一个IP packet。
这个 TCP packet 接下来会进入链路层,链路层会在封包中加入 frame 头部,里面包含了本地内置网卡的MAC地址以及网关(本地路由器)的 MAC 地址。像前面说的一样,如果内核不知道网关的 MAC 地址,它必须进行 ARP 广播来查询其地址。
到了现在,TCP 封包已经准备好了,可以使用下面的方式进行传输:
假设要通过http发送hello, world这12个字节,但是实际上要发送多少个字节呢?如下:
16字节的数据帧头+ 20字节的ip头 + 20字节的tcp头+ 288字节的http头 + 12字节文本
也就是说为了发送12个字节的数据,总共得发送356个字节,有效内容仅占了4%不到。
参考
- what-of-traffic-is-network-overhead-on-top-of-http-s-requests
- Hadi Hariri — HTTP/2 – What do I need to know?
- WEB加速,协议先行腾讯技术工程事业群基础架构部高级工程师lancelot演讲
- HTTP 2.0: why and how by Simone Bordet
- HTTP1.1中的一些优化策略失效
- O’Reilly HTTP/2
- Flow control
- http3 based on quic
浏览器对同一ip进行请求的最大并发连接数是不一样的:IE11 、IE10 、chrome、Firefox 的并发连接数是 6个,IE9是10个。。