OkHttp通过ConnectionPool做到tcp连接复用(在Timeout内),所以并不是每个http都去建立一个tcp连接
自定义通讯协议,使用java socket实现客户端和服务端。需要注意的是分包问题和黏包问题
1. http请求中tcp连接的复用(http -keep alive是应用层的实现,与tcp kkepalive那个2小时没关系)
2. 自定义通讯协议
http这种属于应用层的协议定义了每个数据包的结构是怎样的。在一些场合下,比如追求通讯速度,自定义加密手段,可能需要自定义结构体。
自己用Socket实现一套server-client通讯模型其实不难。
server这边,先确定自己对外公布的ip,port。然后起一个serverSocket,死循环去accept,每次accept到一个就添加到一个列表中,同时用线程池去执行一个死跑从socket中read的runnable。
client这边,根据server的ip和port去连接上,client主动发消息(byte,int,String类型都行),server这边读到信息,给出response,clinent再读取server的回话,就跟两个人之间你一句我一句说话一样。整个过程中 保持了长连接,只要任何一方没有手动设置socket.setSoTimeout的话,放一晚上都不会断开。
一个重点是双方发送的消息格式,即两个人交流的语言,如果全部是String的话,那就跟http很像了,当然任何数据格式从socket发出去最终都是以byte的形式发出去的(比如string会用utf-8或者gbk编码成byte数组)。
google的protoBuffer最重要的两个方法writeTo(object转成byte数组)和parseFrom(byte数组转成object)。
基于Java Socket的自定义协议,实现Android与服务器的长连接(二),基于这篇文章,可以将数据类型定义为统一的protocol,protocol的要素包括:
协议版本
数据类型(数据类协议,数据ack类协议,心跳类协议,心跳ack类协议)
数据长度(这很重要)
消息id
扩展字段
协议版本要做到向后兼容,基本上只添加数据实体不删除数据实体就可以了
数据类型必需的三个要素是:
长度,版本号,数据类型 (比方说0表示业务数据,1表示数据ack,2表示心跳,3表示心跳ack)。
扩展字段类似于extra,可以用json或者别的什么去实现。
3. tcp的分包和粘包问题
tcp发包的时候,如果一个包过大,会拆成两个包发(分包)。如果太小,发送方会攒着和下一个包一起发(粘包),tcp为了提高效率(使用Nagle算法)会缓冲N个包后再一起发出去。作为接收方并不知道收到的包是一个完整的包还是被拆分的还是由两个包合并而来。
可能发生分包和粘包的原因包括:
1、要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
2、待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。
3、要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包。
4、接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
我们都知道TCP属于传输层的协议,传输层除了有TCP协议外还有UDP协议。那么UDP是否会发生粘包或拆包的现象呢?答案是不会。UDP是基于报文发送的,从UDP的帧结构可以看出,在UDP首部采用了16bit来指示UDP数据报文的长度,因此在应用层能很好的将不同的数据报文区分开,从而避免粘包和拆包的问题。而TCP是基于字节流的,虽然应用层和TCP传输层之间的数据交互是大小不等的数据块,但是TCP把这些数据块仅仅看成一连串无结构的字节流,没有边界;另外从TCP的帧结构也可以看出,在TCP的首部没有表示数据长度的字段,基于上面两点,在使用TCP传输数据时,才有粘包或者拆包现象发生的可能。
虽然有分包和粘包问题,但是作为传输层的tcp能够保证发送出去的顺序和接收到的顺序是一致的。
那么基本的解决方法也很成熟了:
1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。
2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
3、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。
另外,http协议是通过添加换行符“ /r/n”这种形式来解决上述问题的
参考TCP粘包,拆包及解决方法
4. java这边socket的inputStream的read方法是会堵塞的
就是read方法一直不返回,Socket只是一座桥梁,并不像本地文件一样,所以无法知道对方是否把话说完了。只有一方调用socket的close方法时才会发送EOF结束符,另一方的read = -1 才能成立,否则read方法就堵塞在那里。
InputStream有一个available()方法:
an estimate of the number of bytes that can be read (or skipped
over) from this input stream without blocking or 0 when it reaches the end of the input stream.
oves) 。不要把这个方法中的返回值当做这个流中所有可能数据的总和(多数情况下这种猜测是错误的)。
tcp的backlog变量
建立TCP连接时需要发送同步SYN报文,然后等待确认报文SYN+ACK,最后再发送确认报文ACK。
如果应用层不能及时接受已被TCP接受的连接,这些连接可能占满整个连接队列,新的连接请求可能不被响应而会超时。如果一个连接请求SYN发送后,一段时间后没有收到确认SYN+ACK,TCP会重传这个连接请求SYN两次,每次重传的时间间隔加倍,在规定的时间内仍没有收到SYN+ACK,TCP将放弃这个连接请求,连接建立就超时了。
BufferedWriter的主要原理是内部保留了一个char[]的数组,每次外部调用write的时候,不是直接写到underlying 的output中,而是system.arrayCopy到自己的char[]数组中,等发现char[]数组填满了,才去flushBuffer,就是把所有缓存的内容一次性写到底层的outputStream中。因为outputStream是一个字节一个字节去写的,每次写都要调用io操作,而io操作是很耗费资源的。所以bufferedWriter一次性写大量的数据,能够有效减少io次数,提高性能。
以TCP/IP协议为例,如何通过wireshark抓包分析?
Content Security Policy 入门教程
两种方式设置csp白名单,一种是服务器在response的header中添加’Content-Security-Policy’这个header,另一种是在html中写meta标签
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; object-src 'none'; style-src cdn.example.org third-party.org; child-src https:">
http请求是一行一行的文字,contentType only affects the body/document.you can use any ISO-8859-1 characters in the header.。ISO-8859-1不支持中文,所以header里面的东西不能写中文。
body和path里面随意了
//网页上传excel表格的header
Content-Disposition: form-data; name=”files[]” filename=”sample.xls”
Content-Type: application/vnd.ms-excel
Content-Disposition的解释
上传文件的话会设置Content-Type为multipart/form-data,并指定boundary的值来标识请求体中内容的分界,而在请求体中,不同的内容(如:文件A和文件B)之间使用boundary的值来标识分界,并且请求体中每部分内容都会有Content-Disposition和Content-Type来指明这部分内容的类型和信息。
后端的话使用ServletFileUpload来解析请求,获得FileItem的List,遍历Item,然后通过Item获得输入流,从输入流中读取上传文件的数据,再构建FileOutputStream输出到磁盘中保存。
如果使用Spring MVC,则可以在接收请求的方法中接收CommonsMultipartFile,并使用transferTo方法保存到磁盘中。
html里面上传文件一般是ajax对象send一个FormData出去,
也有Base64编码一遍然后在服务端base64解码的。主要是html5标准中添加了新的FileReader接口,可以读取客户端文件内容,所以很多开发就调用FileReader的readAsDataURL方法去将文件的内容变成DATA URL形式的字符串
不过这么干还是有缺点的
- Data URL形式的图片不会被浏览器缓存,这意味着每次访问这样页面时都被下载一次,
但可通过在css文件的background-image样式规则使用Data URI Scheme,使其随css文件一同被浏览器缓存起来)。- Base64编码的数据体积通常是原数据的体积4/3,
也就是Data URL形式的图片会比二进制格式的图片体积大1/3。- 移动端性能比较低。
dig +trace baidu.com
nslookup www.youtube.com 1.1.1.1 //指定server,国内因为dns污染,返回的结果是错误的
nslookup -vc google.com 8.8.8.8 // -vc是指强制走tcp查询dns
nslookup -d www.163.com //显示ttl
nslookup -> set debug -> www.163.com //这三条走完是一样的,类似于交互模式
dig挖出DNS的秘密
dns查询也可以使用tcp
The Transmission Control Protocol (TCP) is used when the response data size exceeds 512 bytes, or for tasks such as zone transfers.
详细的http-content-type表格
关于content-type,找到一篇介绍
关于Http header常用字段理解Http Header
Http底层TCP ,ACK 等等需要tcpcump结合wireShark抓包
下面是几个常见的Content-Type:
1.text/html
2.text/plain
3.text/css
4.text/javascript
5.application/x-www-form-urlencoded
6.multipart/form-data
7.application/json
8.application/xml
…
前面几个都很好理解,都是html,css,javascript的文件类型,后面四个是POST的发包方式。
非官方的mime-type大全
MDN上收录的mime-type
X-Content-Type-Options:nosniff.就是说服务器返回的Response中如果包含这个header的话,script和styleSheet元素会拒绝错误的MIME类型的响应。主要是为了防止给予MIME类型的混淆攻击
Referrer Policy: unsafe-url
unsafe-url
后台在response中返回一个302,并在response header中添加header:location。直接把前端网页重定向到新的位置
服务器压测工具
npm install -g loadtest ##一个node的压力测试的web client
loadtest -n 100 -k http://localhost:8000/api/somebackend # -n表示发送100次 -k 表示keep-alive
loadtest -c 10 –rps 200 http://mysite.com/ # -c表示client,创建10个client , –rsp表示每秒的请求数量
loadtest -k -H ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8’ -H “User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36” –rps 1 https://www.baidu.com/
注意: 这种短期创建大量外网连接的行为会对路由器造成一定压力。。。。
ab(ApacheBench) - a simple ,single-threaded command line tool for benchemarking an HTTP server.
因为是单线程的,所以并不能利用多核cpu的优势对server施加充分的负载。一般这么用
ab -n 1000 -c 100 http://example.com/
ab -n-c :
wrk -H ‘Host: localhost’ -H ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’ -H ‘Connection: keep-alive’ -d 600 -c 1024 -t 8 http://127.0.0.1:8080/plaintext
wrk -H ‘Host: localhost’ -H ‘Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’ -H ‘Connection: keep-alive’ -d 600 -c 1024 -t 8 http://127.0.0.1:8080/plaintext
wrk是一种http 跑分工具,tcp和udp测速需要iperf
how-to-use-traceroute-and-mtr-to-diagnose-network-issues
.well-known的意思,其实就跟robot.txt差不多。一种为了能够在客户端发起请求(但此时并不清楚url空间的允许策略,贸然访问万一侵权了呢)获得一些有用的信息。于是RFC就提出来搞一个专门的.well-known的path,这下面的位置都是广而周知的,大家都知道是特定的用途的。
nc其实就是netcat了,功能比较强大
nc -vz 192.168.0.181 20060 //测试TCP端口可用性的方法
nc -vuz IP port //测试udp端口可用性的方式,但实际测下来,就算server上udp port没开,还是会返回succeeded,所以这个也不可靠
netcat还可以实现udp聊天
服务器上
nc -ul 1080 // 会卡在这里,等待新的消息到达1080端口
//客户端这边
nc -u x.x.x.x 1080 //也会卡在这里,不过可以输入文字,按下回车,服务器这边就能收到消息了
wget –spider www.baidu.com //wget还有一个spider模式
“ping -l 1472 -f www.baidu.com”
udp的MTU参数
https的url是加密的吗?是的,
所以你可以把账户密码写在url后面发出去,这样是安全的,外界无法截获你的隐私信息.
但着实不应该这样做,
在浏览器地址栏和浏览器历史记录里面都留下了账户密码。可能会在http的referer里面带上你的url和隐私信息
但是第一次client hello的时候host还是会明文写在包里,后面的query Parameters由于跟client hello无关,所以是加密的.
Server Name Indication
SNI breaks the ‘host’ part of SSL encryption of URLs. You can test this yourself with wireshark. There is a selector for SNI
// http post请求,设置content-type = Application/json,body里面放一个int或者long,实际传输的是string还是long?(猜测是string,因为要走utf-8之类的encoding过一遍,因为http是text-based协议)
这事是有区别的,比如要post出去一个”6”,
字符串6的ascii码是
二进制:0011 0110
十进制:54
十六进制:36
只需要一个字节
int 类型数字6 在java里是4个字节,
在c语言里是2个或者四个字节。
那么这个数字再大一点呢
字符串66666666需要八个字节
int 类型数字66666666 在java里是4个字节,
在c语言里是2个或者四个字节。
需要四个字节
整体来讲,JSON 是文本的格式,整数和浮点数应该更占空间而且更费时。
这就涉及到json和protobuff等二级制协议的比对了,从上面来看,如果你的内容是整数或者浮点数比较多的话,一大长串的数字用string的话就得花上很多内存,但是用int或者float的话可能四个字节就搞定了。所以这事没法绝对的说
都知道传输的都是byte数组,猜测传的类型是文字形式的。因为读取的时候多数是utf-8形式的,没办法特意指出这块byte是int还是string的一部分
post一个json出去的时候
{"name":"john"}
//事实上在byte层面是发送了这么些byte
123 {
34 "
110 n
97 a
109 m
101 e
34 "
58 :
34 "
106 j
111 0
104 h
110 n
34 "
125 }
这些标点符号都发送出去了,也就是占用的byte.
application/x-www-form-urlencoded
multipart/form-data
application/json
text/xml
application/json的post请求的长这样
POST / HTTP/1.1
Host: www.baidu.com
User-Agent: ...
Content-Length:27
Cookie: session=fsdaf;aaa=dfasf;......
{"input1":"xxx","input2":"oo加密过的xxxxo","remember":false}
application/x-www-form-urlencoded(浏览器的原生 form 表单)的post请求的长这样
POST / HTTP/1.1
Host: www.baidu.com
User-Agent: ...
Content-Length:27
Cookie: session=fsdaf;aaa=dfasf;......
name=user&password=password
multipart/form-data:(表单格式的)这一种是表单格式的,数据类型如下
POST / HTTP/1.1
Host: www.baidu.com
User-Agent: ...
Content-Length:27
Cookie: session=fsdaf;aaa=dfasf;......
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
text/xml:这种直接传的xml的post请求的长这样
POST / HTTP/1.1
Host: www.baidu.com
User-Agent: ...
Content-Length:27
Cookie: session=fsdaf;aaa=dfasf;......
<!--?xml version="1.0"?-->
<methodcall>
<methodname>examples.getStateName</methodname>
<params>
<param>
<value><i4>41</i4></value>
</params>
</methodcall>
data%3D%7B%22name%22%3A%22john%22%2C%22age%22%2C20%2C%22time%22%2C6%7D
这种东西通常是懒得看的,
需要转码一下,粘贴到这个里面去就行了,或者自己encodeURIComponent一下就好
其实是: data={“name”:”john”,”age”,20,”time”,6}
HTTP 为超文本传输协议,整个的 HTTP 报文,如果按编程语言里面的类型来分的话,就是一大段字符串。值得注意的是,不像 JSON,application/x-www-form-urlencoded 的方式对复杂类型(例如数组)的处理,并没有严格的标准。有的接口使用 key[]=a&key[]=b 来表示数组 key: [‘a’, ‘b’],(这也是最常见的,jQuery、superagent等客户端会如此编码),有的库则将数组编码为:key=a&key=b,有的则是携带下标进行编码:key[0]=a&key[1]=b……十分混乱。所以如果是数组且数组的每一项为简单基本类型,而且非要用 application/x-www-form-urlencoded 进行序列化,那么不如用英文逗号分隔的字符串来表示。如果是嵌套对象……那么还是尽早使用 JSON 吧。
jwt事实上就是服务器颁发给客户端一个加密后(只有server才能解密)的字符串,客户端每次请求的时候就在header里面带上这个字符串。sessionless-authentication-withe-jwts
If an attacker somehow manages to steal a user’s JWT, then there’s unfortunately not much that can really be done. To minimize damages, you should design your application to require reauthentication before performing any high profile transaction such as a purchase or the changing of a password. And your JWTs should also have an expiration date. That way a compromised JWT will only work for so long.
但是如果有人把这个header搞到,就能向服务器声称自己是该用户。服务器是只认这个jwt字符串不认人的,碰到这种情况其实也没什么解决办法,最多把jwt的有效期设置的短一点。
子网掩码表示一个网段的方式
优先级为先检查hosts.deny,再检查hosts.allow,
后者设定可越过前者限制,
例如:
a.限制所有的ssh,
除非从218.64.87.0 - 127上来。
hosts.deny:
in.sshd:ALL
hosts.allow:
in.sshd:218.64.87.0/255.255.255.128
b.封掉218.64.87.0 - 127的telnet
hosts.deny
in.sshd:218.64.87.0/255.255.255.128
c.限制所有人的TCP连接,除非从218.64.87.0 - 127访问
hosts.deny
ALL:ALL
hosts.allow
ALL:218.64.87.0/255.255.255.128
d.限制218.64.87.0 - 127对所有服务的访问
hosts.deny
ALL:218.64.87.0/255.255.255.128
其中冒号前面是TCP daemon的服务进程名称,通常系统
进程在/etc/inetd.conf中指定,比如in.ftpd,in.telnetd,in.sshd
其中IP地址范围的写法有若干中,主要的三种是:
1.网络地址–子网掩码方式:
218.64.87.0/255.255.255.0
2.网络地址方式(我自己这样叫,呵呵)
218.64.(即以218.64打头的IP地址)
3.缩略子网掩码方式,即数一数二进制子网掩码前面有多少个“1”比如:
218.64.87.0/255.255.255.0 – 218.64.87.0/24
比方说:在子网192.168.20.0/30中,能接收到目的地址为192.168.20.3的IP分组的最大主机数是()
到这个在线子网掩码计算器中输入,结果是
可用ip 2
掩码 255 255 255 252
网络 192 168 20 0
第一可用 192 168 20 1
第二可用 192 168 20 2
广播 192 168 20 3
解释下就是 30 说明前面有30个1,后面只剩下俩位,也就是四种可能,但有俩是要保留给网络和广播的,所以只剩下2个
NAPT原理
简单来说,在NAT网关上会有一张映射表,表上记录了内网向公网哪个IP和端口发起了请求,然后如果内网有主机向公网设备发起了请求,内网主机的请求数据包传输到了NAT网关上,那么NAT网关会修改该数据包的源IP地址和源端口为NAT网关自身的IP地址和任意一个不冲突的自身未使用的端口,并且把这个修改记录到那张映射表上。最后把修改之后的数据包发送到请求的目标主机,等目标主机发回了响应包之后,再根据响应包里面的目的IP地址和目的端口去映射表里面找到该转发给哪个内网主机。这样就实现了内网主机在没有公网IP的情况下,通过NAPT技术借助路由器唯一的一个公网IP来访问公网设备。
在较早以前的 RFC 1918 文档中对私有地址有相关的说明。
因特网域名分配组织IANA组织(Internet Assigned Numbers Authority)保留了以下三个IP地址块用于私有网络。
10.0.0.0 - 10.255.255.255 (10/8比特前缀)
172.16.0.0 - 172.31.255.255 (172.16/12比特前缀)
192.168.0.0 - 192.168.255.255 (192.168/16比特前缀)
我们可以看到其中有1个A类地址块,32个B类地址块和256个C类地址块。主流的家用路由器使用C类私有地址作为路由器LAN端的IP地址较多,所以我们可以看到路由器设置页面的IP一般都为192.168开头。
tcp keep-alive和http的keep-alive是两回事 http keep-alive是由webserver负责实现的。 关键字:http keepalive implementation
http1.0中每个tcp连接用完了就关闭掉
http1.1中每个连接用完了不关闭,(保留一个keepAlive时间,在OkHttp里面默认一条连接在没有使用过的情况下保留5分钟才关闭)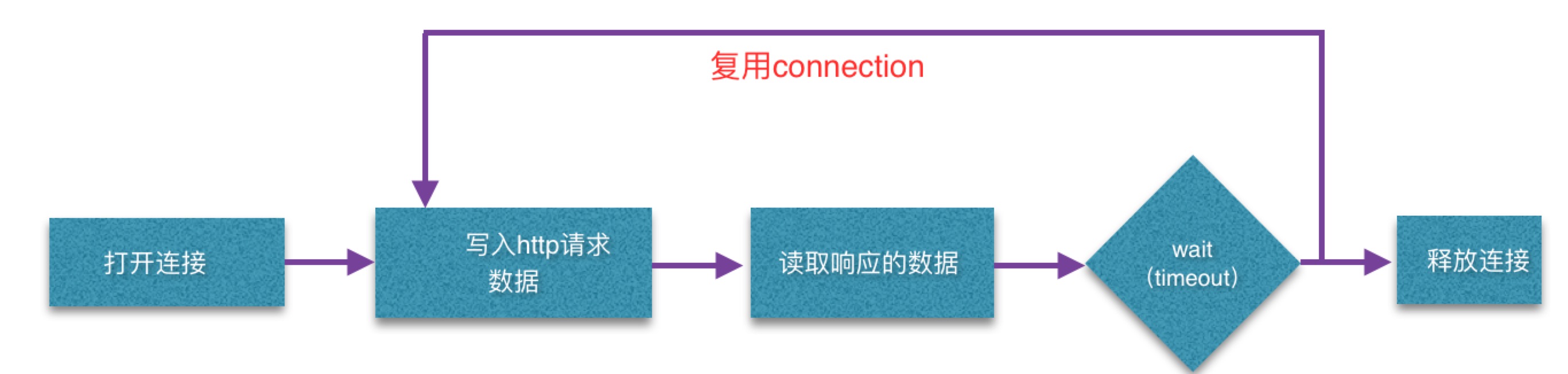
这篇回答里解释了http keep-alive是为了让后续的http请求复用这一条tcp连接。而tcp的keep alive则是定期发小的包。
另外,http server并不会主动去问client是否还连着,只需要起一个timeout(到时间就掐掉这条tcp)就行了。下次客户端再来发起请求,重新起一条tcp吧。
但是http keepalive在有些时候也是有问题的(http-keepAlive的缺点,多个请求同时到达就会因为头部阻塞而延迟,这种时候还不如重新搞一个socket处理)
虽说HTTP/1.1 Keep-Alive特性支持多个请求在同一个连接上排队发送,在浏览器端正常的HTML等资源请求,会带来线头阻塞弊端,后一个请求依赖于前一个请求完成,一旦出现阻塞,后续请求只能排队等待。
移动APP后端网络处理一些问题记录
HTTP/1.1 Pipelining(建立在Keep-Alive持久化基础之上,中文译为管线化,支持连续的幂等的GET/HEAD方法请求,实际环境下,并没有被浏览器所支持。同一个连接,处理同样的三次请求-响应)
arp caches
hash算法和加密
哈希算法是不可逆的,而加密算法是可逆的
哈希(Hash)是将目标文本转换成具有相同长度的、不可逆的杂凑字符串(或叫做消息摘要),而加密(Encrypt)是将目标文本转换成具有不同长度的、可逆的密文。
具体来说,两者有如下重要区别:
1、哈希算法往往被设计成生成具有相同长度的文本,而加密算法生成的文本长度与明文本身的长度有关。
例如,设我们有两段文本:“Microsoft”和“Google”。两者使用某种哈希算法得到的结果分别为:“140864078AECA1C7C35B4BEB33C53C34”和“8B36E9207C24C76E6719268E49201D94”,而使用某种加密算法的到的结果分别为“Njdsptpgu”和“Hpphmf”。可以看到,哈希的结果具有相同的长度,而加密的结果则长度不同。实际上,如果使用相同的哈希算法,不论你的输入有多么长,得到的结果长度是一个常数,而加密算法往往与明文的长度成正比。
2、哈希算法是不可逆的,而加密算法是可逆的。
这里的不可逆有两层含义,一是“给定一个哈希结果R,没有方法将E转换成原目标文本S”,二是“给定哈希结果R,即使知道一段文本S的哈希结果为R,也不能断言当初的目标文本就是S”。其实稍微想想就知道,哈希是不可能可逆的,因为如果可逆,那么哈希就是世界上最强悍的压缩方式了——能将任意大小的文件压缩成固定大小。(这话的意思就是不同的内容可能会有相同的hashCode,所以在https加密中)
加密则不同,给定加密后的密文R,存在一种方法可以将R确定的转换为加密前的明文S。
https流程
1.浏览器将自己支持的一套加密规则发送给网站。
2.网站从中选出一组加密算法与HASH算法,并将自己的身份信息以证书的形式发回给浏览器。证书里面包含了网站地址,加密公钥,以及证书的颁发机构等信息。
第 2步时服务器发送了一个SSL证书给客户端,SSL 证书中包含的具体内容有:
(1)证书的发布机构CA
(2)证书的有效期
(3)公钥
(4)证书所有者
(5)签名
数字签名是用来验证数据完整性的,首先将公钥与个人信息用一个Hash算法生成一个消息摘要,Hash算法是不可逆的,且只要内容发生变化,那生成的消息摘要将会截然不同。然后CA再用它的私钥对消息摘要加密,最终形成数字签名。还把原始信息和数据签名合并,形成一个全新的东西,叫做“数字证书”
客户端在接受到服务端发来的SSL证书时,会对证书的真伪进行校验,以浏览器为例说明如下:
(1)首先浏览器读取证书中的证书所有者、有效期等信息进行一一校验
(2)浏览器开始查找操作系统中已内置的受信任的证书发布机构CA,与服务器发来的证书中的颁发者CA比对,用于校验证书是否为合法机构颁发
(3)如果找不到,浏览器就会报错,说明服务器发来的证书是不可信任的。
(4)如果找到,那么浏览器就会从操作系统中取出 颁发者CA 的公钥,然后对服务器发来的证书里面的签名进行解密
(5)浏览器使用相同的hash算法计算出服务器发来的证书的hash值,将这个计算的hash值与证书中签名做对比
(6)对比结果一致,则证明服务器发来的证书合法,没有被冒充
(7)此时浏览器就可以读取证书中的公钥,用于后续加密了
4、所以通过发送SSL证书的形式,既解决了公钥获取问题,又解决了黑客冒充问题,一箭双雕,HTTPS加密过程也就此形成
我是这样理解这个https是如何解决中间人攻击问题的:
数字证书包括:证书的发布机构CA,证书的有效期,公钥,证书所有者,签名(前面几个明文的hash值)
作为一个中间人:我可以伪造证书的发布机构CA,证书的有效期,证书所有者,但是公钥我必须得换成我自己的啊(百度公钥加密的东西我又解不开),好了,这下明文内容肯定要改了。这下导致签名(hash值)不对了,客户端肯定不认,用百度发过来的的?当然不行了。瞎写一个?客户端拿着操作系统内置的CA证书去解密你这段瞎写的hash,肯定不对。唯一能实现对的上的情况是。让CA用自己的私钥把(百度的证书的发布机构CA,百度证书的有效期,我的公钥,百度的证书所有者这些东西加密一遍,这样客户端用CA解密出来的hash也一样了)。但是这怎么可能?