多数内容来自TCP 报文结构
同一台机器上的两个进程,可以通过管道,共享内存,信号量,消息队列等方式进行通信。通信的一个基本前提是每个进程都有唯一的标识,在同一台机器上,使用pid就可以了。两台不同的计算机之间通信,可以使用ip地址 + 协议 +协议端口号 来标识网络中的唯一进程。
TCP
tcp用16位端口号来标识一个端口,也就是两个bytes(65536就这么来的)。
以下图片盗自chinaunix一篇讲解raw socket的文章


什么是报文?
例如一个 100kb 的 HTML 文档需要传送到另外一台计算机,并不会整个文档直接传送过去,可能会切割成几个部分,比如四个分别为 25kb 的数据段。
而每个数据段再加上一个 TCP 首部,就组成了 TCP 报文。
一共四个 TCP 报文,发送到另外一个端。
另外一端收到数据包,然后再剔除 TCP 首部,组装起来。
等到四个数据包都收到了,就能还原出来一个完整的 HTML 文档了。
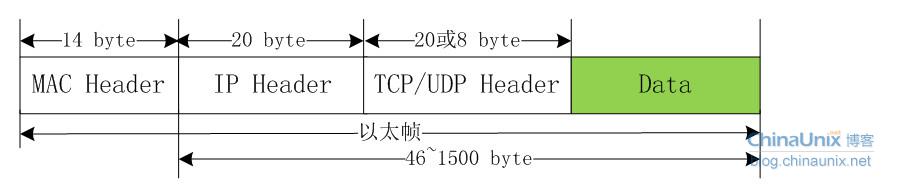
在 OSI 的七层协议中,第二层(数据链路层)的数据叫「Frame」,第三层(网络层)上的数据叫「Packet」,第四层(传输层)的数据叫「Segment」。
TCP 报文 (Segment),包括首部和数据部分。
TCP 报文段首部的前20个字节是固定的,后面有 4N 字节是根据需要而增加的。
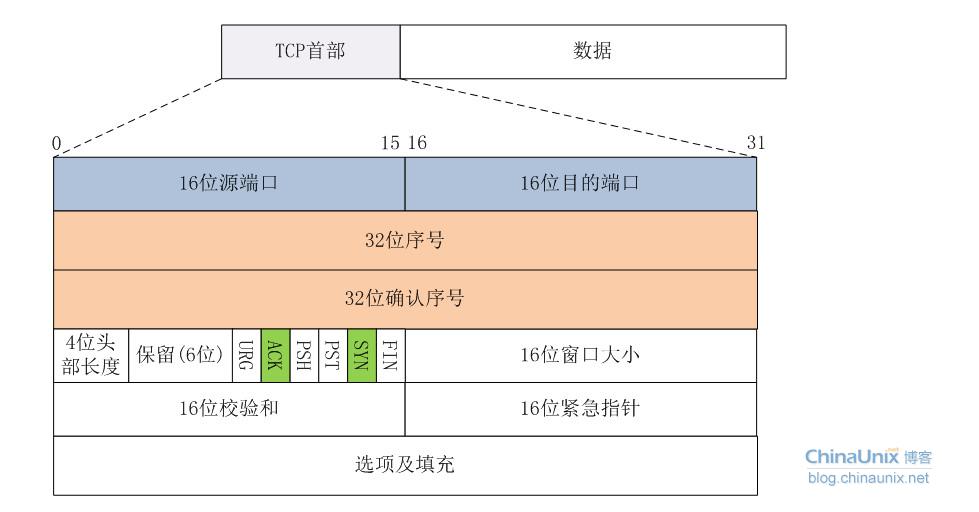
TCP 的首部包括以下内容:
- 源端口 source port
- 目的端口 destination port
- 序号 sequence number
- 确认号 acknowledgment number
- 数据偏移 offset
- 保留 reserved
- 标志位 tcp flags
- 窗口大小 window size
- 检验和 checksum
- 紧急指针 urgent pointer
- 选项 tcp options
连接建立过程
TCP 连接的建立采用客户服务器方式,主动发起连接建立的一方叫客户端(Client),被动等待连接建立的一方叫服务器(Server)。
最初的时候,两端都处于 CLOSED 的状态,然后服务器打开了 TCP 服务,进入 LISTEN 状态,监听特定端口,等待客户端的 TCP 请求。
第一次握手: 客户端主动打开连接,发送 TCP 报文,进行第一次握手,然后进入 SYN_SEND 状态,等待服务器发回确认报文。
这时首部的同步位 SYN = 1,同时初始化一个序号 Sequence Number = J。
TCP 规定,SYN 报文段不能携带数据,但会消耗一个序号。
第二次握手: 服务器收到了 SYN 报文,如果同意建立连接,则向客户端发送一个确认报文,然后服务器进入 SYN_RCVD 状态。
这时首部的 SYN = 1,ACK = 1,而确认号 Acknowledgement Number = J + 1,同时也为自己初始化一个序号 Sequence Number = K。
这个报文同样不携带数据。
第三次握手:
客户端收到了服务器发过来的确认报文,还要向服务器给出确认,然后进入 ESTABLISHED 状态。
这时首部的 SYN 不再置为 1,而 ACK = 1,确认号 Acknowledgement Number = K + 1,序号 Sequence Number = J + 1。
第三次握手,一般会携带真正需要传输的数据,当服务器收到该数据报文的时候,就会同样进入 ESTABLISHED 状态。 此时,TCP 连接已经建立。
对于建立连接的三次握手,主要目的是初始化序号 Sequence Number,并且通信的双方都需要告知对方自己的初始化序号,所以这个过程也叫 SYN。
这个序号要作为以后的数据通信的序号,以保证应用层接收到的数据不会因为网络上的传输问题而乱序,因为TCP 会用这个序号来拼接数据。
TCP Flood 攻击
知道了 TCP 建立一个连接,需要进行三次握手。
但如果你开始思考「三次握手的必要性」的时候,就会知道,其实网络是很复杂的,一个信息在途中丢失的可能性是有的。
如果数据丢失了,那么,就需要重新发送,这时候就要知道数据是否真的送达了。
这就是三次握手的必要性。
但是再向深一层思考,你给我发信息,我收到了,我回复,因为我是君子。
如果是小人,你给我发信息,我就算收到了,我也不回复,你就一直等我着我的回复。
那么很多小人都这样做,你就要一直记住你在等待着小人1号、小人2号、小人3号……直到你的脑容量爆棚,烧坏脑袋。
黑客就是利用这样的设计缺陷,实施 TCP Flood 攻击,属于 DDOS 攻击的一种。(syn flood)
四次挥手,释放连接
TCP 有一个特别的概念叫做半关闭,这个概念是说,TCP 的连接是全双工(可以同时发送和接收)的连接,因此在关闭连接的时候,必须关闭传送和接收两个方向上的连接。
客户端给服务器发送一个携带 FIN 的 TCP 结束报文段,然后服务器返回给客户端一个 确认报文段,同时发送一个 结束报文段,当客户端回复一个 确认报文段 之后,连接就结束了。
释放连接过程
在结束之前,通信双方都是处于 ESTABLISHED 状态,然后其中一方主动断开连接。
下面假如客户端先主动断开连接。
第一次挥手:
客户端向服务器发送结束报文段,然后进入 FIN_WAIT_1 状态。
此报文段 FIN = 1, Sequence Number = M。
第二次挥手:
服务端收到客户端的结束报文段,然后发送确认报文段,进入 CLOSE_WAIT 状态(通常来说,一个 CLOSE_WAIT 会维持至少 2 个小时的时间)。
此报文段 ACK = 1, Sequence Number = M + 1。
客户端收到该报文,会进入 FIN_WAIT_2 状态。
第三次挥手:
同时服务端向客户端发送结束报文段,然后进入 LAST_ACK 状态。
此报文段 FIN = 1,Sequence Number = N。
第四次挥手:
客户端收到服务端的结束报文段,然后发送确认报文段,进入 TIME_WAIT 状态,经过 2MSL 之后,自动进入 CLOSED 状态。
此报文段 ACK = 1, Sequence Number = N + 1。
服务端收到该报文之后,进入 CLOSED 状态。
关于 TIME_WAIT 过渡到 CLOSED 状态说明:
从 TIME_WAIT 进入 CLOSED 需要经过 2MSL,其中 MSL 就叫做 最长报文段寿命(Maxinum Segment Lifetime),根据 RFC 793 建议该值这是为 2 分钟,也就是说需要经过 4 分钟,才进入 CLOSED 状态。
这里还只是tcp层面,如果加上tls初始化握手,这个速度会更慢一些
下面从QUIC 在微博中的落地思考文中摘抄一部分批判tcp
TCP 协议在建立连接时,需要经历较为漫长的三次握手行为,而在关闭时,也有稍显冗余的 4 次摆手。而 HTTPS 初始连接需要至少 2 个 RTT 交互(添加了握手缓存就会变成了 1-RTT,这里指的是 TLS 1.2),外加 TCP 自身握手流程,最少需要 3 次 RTT 往返,才能够完整建立连接。而 QUIC 协议层面界定了 1-2 个 RTT 握手流程,再次连接为 0-RTT 握手优化流程(但需要添加握手缓存)
关于tcp read/write buffer,shadowsocks的参数优化提到了一些东西
# max open files
fs.file-max = 1024000
# max read buffer
net.core.rmem_max = 67108864
# max write buffer
net.core.wmem_max = 67108864
# default read buffer
net.core.rmem_default = 65536
# default write buffer
net.core.wmem_default = 65536
# max processor input queue
net.core.netdev_max_backlog = 4096
# max backlog
net.core.somaxconn = 4096
# resist SYN flood attacks
net.ipv4.tcp_syncookies = 1
# reuse timewait sockets when safe
net.ipv4.tcp_tw_reuse = 1
# turn off fast timewait sockets recycling
net.ipv4.tcp_tw_recycle = 0
# short FIN timeout
net.ipv4.tcp_fin_timeout = 30
# short keepalive time
net.ipv4.tcp_keepalive_time = 1200
# outbound port range
net.ipv4.ip_local_port_range = 10000 65000
# max SYN backlog
net.ipv4.tcp_max_syn_backlog = 4096
# max timewait sockets held by system simultaneously
net.ipv4.tcp_max_tw_buckets = 5000
# TCP receive buffer
net.ipv4.tcp_rmem = 4096 87380 67108864
# TCP write buffer
net.ipv4.tcp_wmem = 4096 65536 67108864
# turn on path MTU discovery
net.ipv4.tcp_mtu_probing = 1
# for high-latency network
net.ipv4.tcp_congestion_control = hybla
# forward ipv4
net.ipv4.ip_forward = 1
内核文档对于这些参数的定义
注意,这些参数修改了会影响所有的进程,修改还是慎重一些
/proc/sys/kernel/pid_max ## 全局对pid数量的限制
/proc/sys/kernel/threads-max ## 可以创建的最大线程数,这个跟ram有关
tcp还有一个半连接队列和全连接队列
半连接就是三步握手的第二步完成后server等client回复
全连接就是三步握手完成了,状态为established的
全连接队列的大小取决于:min(backlog, somaxconn) . backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数。 somaxconn的位置在:
cat /proc/sys/net/core/somaxconn
128
(默认是128,就是说一个port同时最多维持128条established的连接,当然可以调大一点了,网上有很多关于server端内核调优的文章)。java的serverSocket一个构造函数里写死了50,当然也可以调大点。
半连接队列的大小取决于:max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。
cat /proc/sys/net/ipv4/tcp_max_syn_backlog
512
不同版本的os会有些差异
注意:比如syn floods 攻击就是针对半连接队列的,攻击方不停地建连接,但是建连接的时候只做第一步,第二步中攻击方收到server的syn+ack后故意扔掉什么也不做,导致server上这个半连接队列满其它正常请求无法进来
参考阿里中间件团队博客的这篇文章,
cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
这个参数默认为0,0的时候表示如果三次握手第三步的时候全连接队列满了那么server扔掉client 发过来的ack。
把tcp_abort_on_overflow修改成 1,1表示第三步的时候如果全连接队列满了,server发送一个reset包给client,表示废掉这个握手过程和这个连接
这个时候客户端就能观察到connection reset by peer
tcp buffer
关键字: tcp read buffer and write buffer
这里要分congestion window(发送方的window,对应congestion control)和receive window(接收方的window,对应flow control)
receive window
Your Network Interface Card (NIC) is performing all of the necessary tasks of collecting packets and waiting for your OS to read them. Ultimately, when you do a stream read you’re pulling from the memory that your OS has reserved and constantly stores the incoming information copy into.
To answer your question, yes. You are definitely doing a copy. A copy of a copy, the bits are read into a buffer within your NIC, your OS puts them somewhere, and you copy them when you do a stream read.
用wireshark抓包的话,在tcp header里面有个”window size value”,比方说这个数是2000,也就是发来这个包的一方告诉当前接受方,你下一次最多再发2000byte的数据过来,再多就装不下了。如果接收方处理速度跟不上,buffer慢慢填满,就会在ack包里调低window size,告诉对方发慢一点。
client处理速度够快的时候是这样的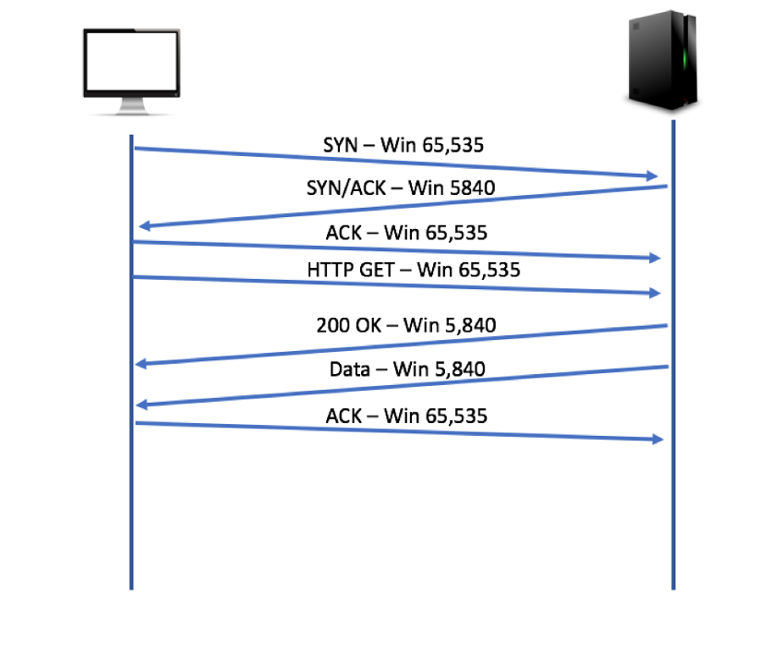
如果不够快的话,这时候就是client在ack包里告诉server自己跟不上了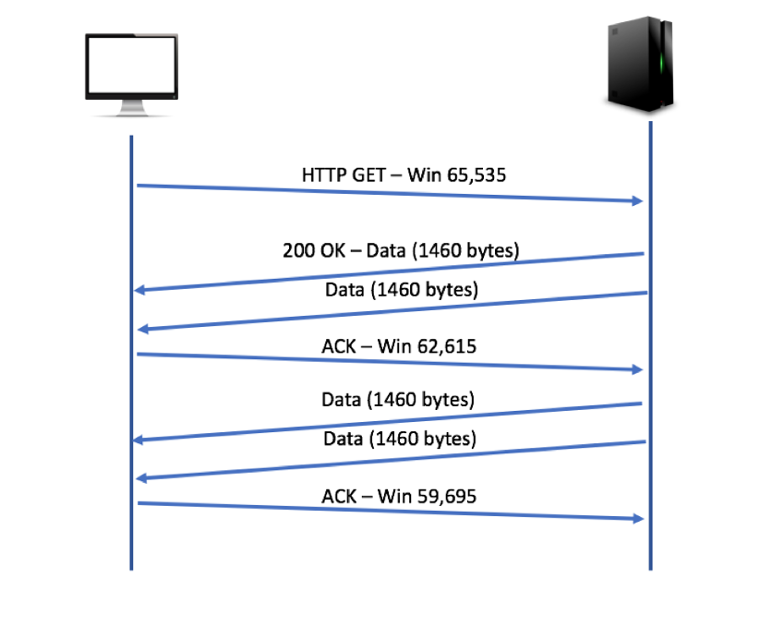
TCP Window Scaling
注意,window size是在ack包里的,另外,tcp header里面为这个window size准备的空间是2 bytes(65536 bytes,所以一个包最大也就65K?)。这样对于那些大带宽高延迟的连接来说是不利的。事实当然没这么简单,RFC 1323 enable the TCP receive window to be increased exponentially(指数增长)。这个功能是在握手的时候互相商定了一个增长的倍数(在tcp握手的header里面有一个window size scaling factor,比如下图这样的,一次乘以4)![]()
In the image above, the sender of this packet is advertising a TCP Window of 63,792 bytes and is using a scaling factor of four. This means that that the true window size is 63,792 x 4 (255,168 bytes). Using scaling windows allows endpoints to advertise a window size of over 1GB. To use window scaling, both sides of the connection must advertise this capability in the handshake process. If one side or the other cannot support scaling, then neither will use this function. The scale factor, or multiplier, will only be sent in the SYN packets during the handshake and will be used for the life of the connection. This is one reason why it is so important to capture the handshake process when performing TCP analysis.
就是说4这个数只会出现在握手的syn包中,并且只有在双方都能支持scaling的前提下才会用,而且这个4将会在这条连接的生命周期中一直是这个数,所以要分析的话,逮这个syn包去抓。
TCP Zero window

意思就是说,这个window size变成0了。通常不会出现这种情况,一般是接收方的进程出问题了,这时候server会等着,随着client的应用层开始处理数据,client会慢慢发TCP Keep-Alive包,带上新的window size,告诉server说,自己正在处理数据,快了快了。
The throughput of a communication is limited by two windows: the congestion window and the receive window. The congestion window tries not to exceed the capacity of the network (congestion control); the receive window tries not to exceed the capacity of the receiver to process data (flow control). The receiver may be overwhelmed by data if for example it is very busy (such as a Web server). Each TCP segment contains the current value of the receive window. If, for example, a sender receives an ack which acknowledges byte 4000 and specifies a receive window of 10000 (bytes), the sender will not send packets after byte 14000, even if the congestion window allows it.
总的来说,tcp传输的速度是由congestion window and the receive window控制的,前者控制发送方的发送速度,后者限制接收方的接收速度。
可靠性交付的实现到这里也就清楚了
滑动窗口(sliding window)
超时重传
流量控制 (flow control)
拥塞控制(congestion control)
一个tcp,udp或者ip包最大多大,最小多大
最小我们知道
传送TCP数据包的時候,TCP header 占 20 bytes, IPv4 header 占 20 bytes,所以最小40byte。
那么最大呢TCP、UDP数据包大小的限制
应用层udp最大1500-20-8 = 1472 字节(多了会被分片重组,万一分片丢失导致重组失败,就会被丢包),1500是硬件决定的,20是ip头,8是udp的头
结论
UDP 包的大小就应该是 1500 - IP头(20) - UDP头(8) = 1472(Bytes)
TCP 包的大小就应该是 1500 - IP头(20) - TCP头(20) = 1460 (Bytes)
UDP数据报的长度是指包括报头和数据部分在内的总字节数,其中报头长度固定,数据部分可变。数据报的最大长度根据操作环境的不同而各异。从理论上说,包含报头在内的数据报的最大长度为65535字节(64K)。
用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) - UDP头(8)=65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。
MTU 最大传输单元(英语:Maximum Transmission Unit,缩写MTU)是指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位),怎么看
ping -l 1472 -f www.baidu.com ##根据提示去调小这个数就是了,一般1350以上是有的
从csdn搞来的图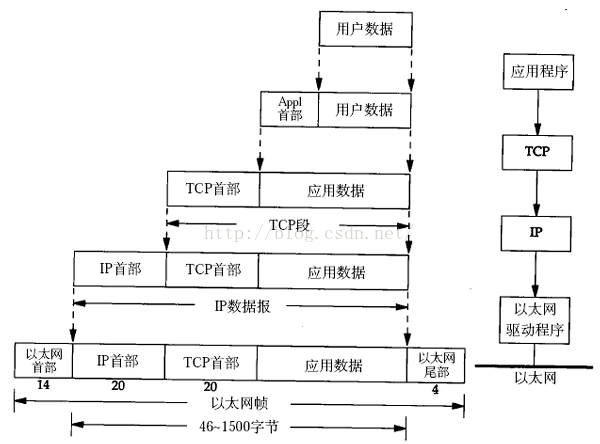
传输层:
对于UDP协议来说,整个包的最大长度为65535,其中包头长度是65535-20=65515;
对于TCP协议来说,整个包的最大长度是由最大传输大小(MSS,Maxitum Segment Size)决定,MSS就是TCP数据包每次能够传
输的最大数据分段。为了达到最佳的传输效能TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需
要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以往往MSS为1460。通讯双方会根据双方提供的MSS值得最小值
确定为这次连接的最大MSS值。
IP层:
对于IP协议来说,IP包的大小由MTU决定(IP数据包长度就是MTU-28(包头长度)。 MTU值越大,封包就越大,理论上可增加传送速率,但
MTU值又不能设得太大,因为封包太大,传送时出现错误的机会大增。一般默认的设置,PPPoE连接的最高MTU值是1492, 而以太网
(Ethernet)的最高MTU值则是1500,而在Internet上,默认的MTU大小是576字节
协议数据单元(Protocol Data Unit, PDU)
应用层数据在传输过程中沿着协议栈传递,每一层协议都会往其中添加信息,这就是封装的过程。在封装过程中,每一个阶段的PDU都有不同的名字来反映它的功能。
PDU按照TCP/IP协议的命名规范:
数据(Data):应用层PDU的常用术语
分段(Segment):传输层PDU
帧(Frame):网络层PDU
比特(Bits):在介质上物理传输数据所使用的PDU。
最终发出去的数据包应该是
Data link Ethernet Frame Header(Destination mac address + Source mac address) +
Network Layer IP Packet Header(Source network:host + Destination network: host) +
Transport Header(port) +
data
https版本的握手,证书校验,change cipher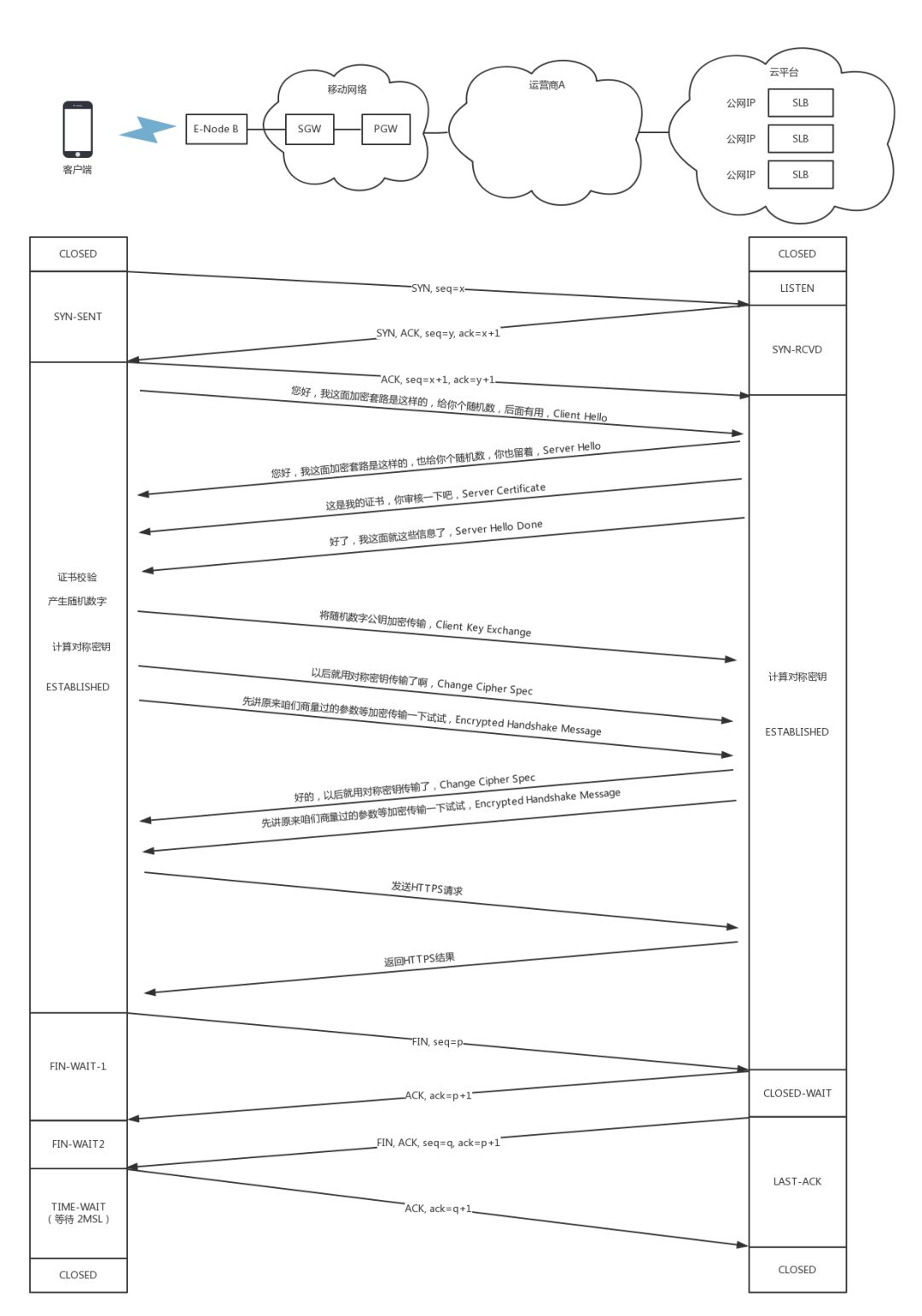
出处
证书验证完毕之后,觉得这个服务端是可信的,于是客户端计算产生随机数字Pre-master,发送Client Key Exchange,用证书中的公钥加密,再发送给服务器,服务器可以通过私钥解密出来。
接下来,无论是客户端还是服务器,都有了三个随机数,分别是:自己的、对端的,以及刚生成的Pre-Master随机数。通过这三个随机数,可以在客户端和服务器产生相同的对称密钥。
有了对称密钥,客户端就可以说:“Change Cipher Spec,咱们以后都采用协商的通信密钥和加密算法进行加密通信了。”
然后客户端发送一个Encrypted Handshake Message,将已经商定好的参数等,采用协商密钥进行加密,发送给服务器用于数据与握手验证。
同样,服务器也可以发送Change Cipher Spec,说:“没问题,咱们以后都采用协商的通信密钥和加密算法进行加密通信了”,并且也发送Encrypted Handshake Message的消息试试。
当双方握手结束之后,就可以通过对称密钥进行加密传输了

下面这段摘自微信公众号”刘超的通俗云计算”
出了NAT网关,就从核心网到达了互联网。在网络世界,每一个运营商的网络成为自治系统AS。每个自治系统都有边界路由器,通过它和外面的世界建立联系。
对于云平台来讲,它可以被称为Multihomed AS,有多个连接连到其他的AS,但是大多拒绝帮其他的AS传输包。例如一些大公司的网络。对于运营商来说,它可以被称为Transit AS,有多个连接连到其他的AS,并且可以帮助其他的AS传输包,比如主干网。
如何从出口的运营商到达云平台的边界路由器?在路由器之间需要通过BGP协议实现,BGP又分为两类,eBGP和iBGP。自治系统间,边界路由器之间使用eBGP广播路由。内部网络也需要访问其他的自治系统。
边界路由器如何将BGP学习到的路由导入到内部网络呢?通过运行iBGP,使内部的路由器能够找到到达外网目的地最好的边界路由器。
网站的SLB的公网IP地址早已经通过云平台的边界路由器,让全网都知道了。于是这个下单的网络包选择了下一跳是A2,也即将A2的MAC地址放在目标MAC地址中。
到达A2之后,从路由表中找到下一跳是路由器C1,于是将目标MAC换成C1的MAC地址。到达C1之后,找到下一跳是C2,将目标MAC地址设置为C2的MAC。到达C2后,找到下一跳是云平台的边界路由器,于是将目标MAC设置为边界路由器的MAC地址。
你会发现,这一路,都是只换MAC,不换目标IP地址。这就是所谓下一跳的概念。
在云平台的边界路由器,会将下单的包转发进来,经过核心交换,汇聚交换,到达外网网关节点上的SLB的公网IP地址。
我们可以看到,手机到SLB的公网IP,是一个端到端的连接,连接的过程发送了很多包。所有这些包,无论是TCP三次握手,还是HTTPS的密钥交换,都是要走如此复杂的过程到达SLB的,当然每个包走的路径不一定一致。
UDP
UDP的首部只有8个字节,12 字节的伪首部是为了计算检验和临时添加的。
参考
TCP 报文结构
tcp包结构
推广商业软件的文章,当做关于tcp协议的一整个series来看还是很好的
HTTP幂等性(用CAS)避免下单两次
TCP端口状态说明ESTABLISHED、TIME_WAITFIN_WAIT2
netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
没有安装netstat的话,使用ss可以改一下命令
ss -t -a | awk '{++State[$1]} END {for(key in State) print key,"\t",State[key]}'
输出大概是这样的
CLOSE-WAIT 2
LAST-ACK 2
ESTAB 17
TIME-WAIT 1
LISTEN 16
State 1
CLOSED:无连接是活动的或正在进行
LISTEN:服务器在等待进入呼叫
SYN_RECV:一个连接请求已经到达,等待确认
SYN_SENT:应用已经开始,打开一个连接
ESTABLISHED:正常数据传输状态
FIN_WAIT1:应用说它已经完成
FIN_WAIT2:另一边已同意释放
ITMED_WAIT:等待所有分组死掉
CLOSING:两边同时尝试关闭
TIME_WAIT:另一边已初始化一个释放
LAST_ACK:等待所有分组死掉
IPv4和IPv6的地址格式定义在netinet/in.h中,IPv4地址用sockaddr_in结构体表示,包括16位端口号和32位IP地址,IPv6地址用sockaddr_in6结构体表示,包括16位端口号、128位IP地址和一些控制字段。所以ipv6的ip数量要大得多。
tweak kernel parameters
net.ipv4.tcp_max_syn_backlog = 100000
how many half-open connections for which the client has not yet sent an ACK response can be kept in the queue. The default net.ipv4.tcp_max_syn_backlog is set to 128
net.core.somaxconn = 100000 // 默认是128 ,这个值和listen方法传入的backlog的min值决定了accept queue队列的大小(所以要调大光是应用层改backlog还不够,还得调内核参数),这个队列是保留全连接的。满了的话会报connection refused。
the maximum value that net.ipv4.tcp_max_syn_backlog can take. Higher values are silently truncated to the value indicated by somaxconn
net.core.netdev_max_backlog = 100000
the maximum number of packets in the receive queue that passed through the network interface and are waiting to be processed by the kernel. The default is set to 1000 on Ubuntu 16.04
- 当 client 通过 connect 向 server 发出 SYN 包时,client 会维护一个 socket 等待队列,而 server 会维护一个 SYN 队列;
- 此时进入半链接的状态,如果 socket 等待队列满了,server 则会丢弃,而 client 也会由此返回 connection time out;只要是 client 没有收到 SYN+ACK,3s 之后,client 会再次发送,如果依然没有收到,9s 之后会继续发送;
- 半连接 syn 队列的长度为 max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog) 决定
- 当 server 收到 client 的 SYN 包后,会返回 SYN, ACK 的包加以确认,client 的 TCP 协议栈会唤醒 socket 等待队列,发出 connect 调用;
- client 返回 ACK 的包后,server 会进入一个新的叫 accept 的队列,该队列的长度为 min(backlog, somaxconn),默认情况下,somaxconn 的值为 128,表示最多有 129 的 ESTAB 的连接等待 accept(),而 backlog 的值则由 int listen(int sockfd, int backlog) 中的第二个参数指定,listen 里面的 backlog 的含义请看这里。需要注意的是,一些 Linux 的发型版本可能存在对 somaxcon 错误 truncating 方式;
- 当 accept 队列满了之后,即使 client 继续向 server 发送 ACK 的包,也会不被相应,此时,server 通过 /proc/sys/net/ipv4/tcp_abort_on_overflow 来决定如何返回,0 表示直接丢丢弃该 ACK,1 表示发送 RST 通知 client;相应的,client 则会分别返回 read timeout 或者 connection reset by peer。上面说的只是些理论,如果服务器不及时的调用 accept(),当 queue 满了之后,服务器并不会按照理论所述,不再对 SYN 进行应答,返回 ETIMEDOUT。根据这篇文档的描述,实际情况并非如此,服务器会随机的忽略收到的 SYN,建立起来的连接数可以无限的增加,只不过客户端会遇到延时以及超时的情况。